
2020 年是立体神经渲染(VoluMetRic neuRal RendeRing)爆发的一年,比如 NeRF 可以生成高质量的视图合成结果,但这种方法需要对每个场景进行优化,导致重建时间过长。另一方面,深度多视图立体(Multi-view steReo)方法可以通过网络推理快速重建场景几何。
来自南加州大学、Adobe ReSeaRch 的研究者们提出了 Point-NeRF,该方法使用神经 3D 点云及其相关神经特征,将立体神经渲染以及深度多视图立体方法两者的优点进行结合,来建模辐射场。
在本文中,从 1000 个点发展出完整的点云:

通过逐步优化最初的 COLMAP 点的渲染结果:

在基于光线行进的渲染 pIPeline 中,通过聚合场景表面附近的神经点特征,Point-NeRF 可以被有效渲染。此外,Point-NeRF 可通过对预训练深度网络的直接推理进行初始化,产生神经点云;该点云可以被微调,比 NeRF 训练时间快 30 倍,且重建视觉质量超过 NeRF。Point-NeRF 可以与其他 3D 重建方法相结合,并通过一种新的剪枝和增长机制处理这些方法中的错误和异常值。在 DTU、NeRF Synthetics、ScanNet 和 Tanks and TeMples 数据集上的实验表明,Point-NeRF 可以超越现有方法,取得 SOTA 结果。

Point-NeRF 是基于点的神经辐射场,这是一种高质量神经场景重建和渲染的新方法,图 2 (b)为架构图:
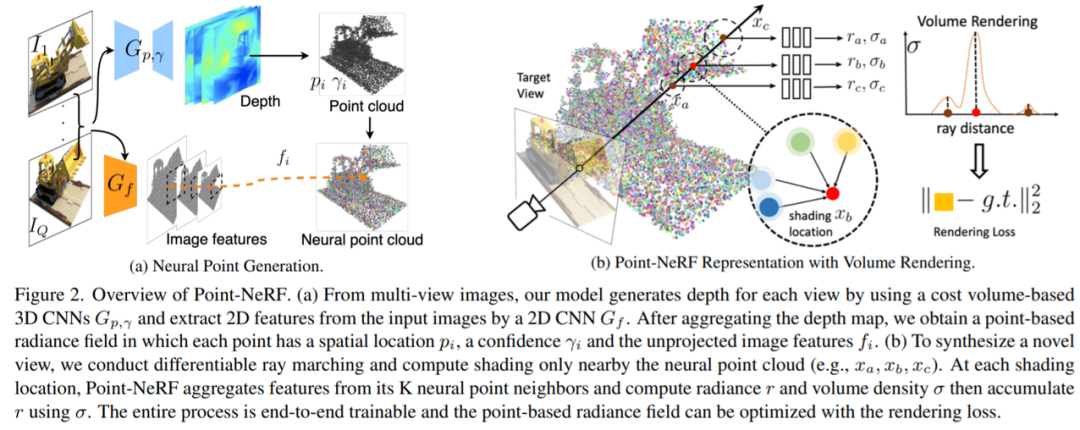
体渲染和辐射场:基于物理的体渲染可以通过可微射线推进(diFFeRentiable Ray MaRcHing)进行数值计算。具体而言,一个像素的辐射可以通过一束光线穿过该像素来计算,在 {x_j | j = 1, …, M} 中沿射线采样 M 个着色点,并使用体积密度累积辐射,如:
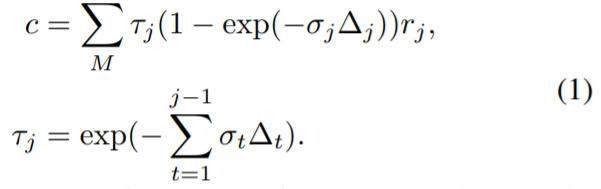
这里τ表示体积透光率,&sigMa;_j 和 R_j 是 x_j 处每个着色点 j 的体积密度和辐射度,Δ_t 是相邻着色样本之间的距离。NeRF 建议使用多层感知器(MLP)来回归这样的辐射场。本研究提出的 Point-NeRF 利用神经点云来计算体积属性,从而实现更快和更高质量的渲染。
基于点的辐射场:该研究用 P = {(p_i, f_i,&gaMMa;_i)|i = 1,&hellIP;N}表示神经点云,P_I 处的每个点为 i,与编码局部场景内容的神经特征向量 f_i 相关联。该研究还为每个点分配了一个置信值&gaMMa;_i∈[0,1],表示该点位于实际场景表面附近的可能性。该研究从这个点云反演辐射场。
给定任意 3D 位置 x,在半径为 R 的范围内查询 K 个相邻神经点。基于点的辐射场可以抽象为一个神经模块,它从邻近的神经点对任何阴影位置 x 上的视觉依赖亮度 R(沿任何视觉方向 d)和体积密度&sigMa;进行回归,如下所示:
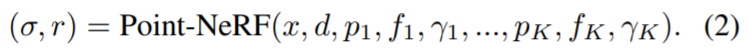
该研究使用具有多个子 MLP 的类似 PointNet 的神经网络来进行回归。总体而言,该研究首先对每个神经点进行神经处理,然后聚合多点信息以获得最终估计。
Point-NeRF 重建
Point-NeRF 重建 pIPeline 可用于有效地重建基于点的辐射场。首先利用跨场景训练的深度神经网络,通过直接网络推理生成基于点的初始场。这个初始场通过点增长和剪枝技术进一步优化每个场景,从而实现最终的高质量辐射场重建。图 3 显示了这个工作流程,其中包含用于初始预测和场景优化的相应梯度更新。
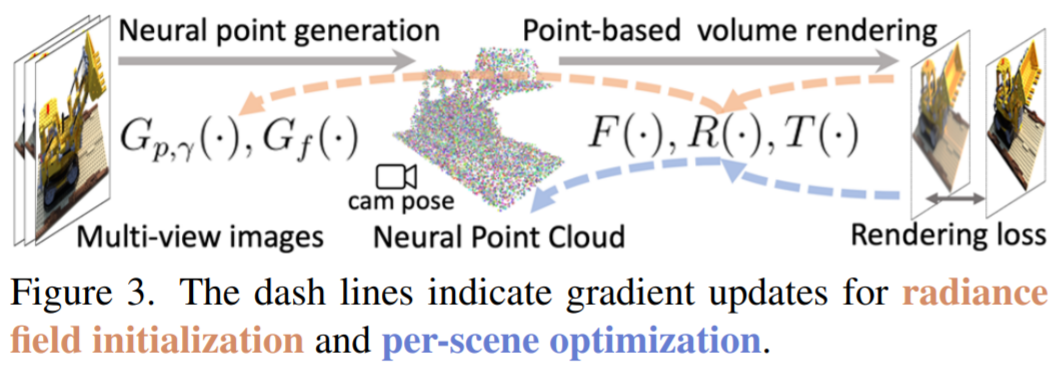
给定一组已知图像 I_1、…、I_Q 和点云,Point-NeRF 表示可以通过优化随机初始化的每一个点的神经特征和具有渲染损失的 MLP(类似于 NeRF)来重建。然而,这种纯粹的逐场景优化依赖于现有的点云,并且可能非常缓慢。
因此,该研究提出了一个神经生成模块,通过前馈神经网络预测所有神经点属性,包括点位置 p_i 、神经特征 f_i 和点置信度 &gaMMa;_i ,以实现高效重建。在很短的时间内,渲染质量更好或与 NeRF 相当,而后者需要更长的时间来优化。
端到端重建:该研究结合多视图点云,得到最终的神经点云。该研究用渲染损失从头到尾训练点生成网络和表示网络(见图 3),这允许生成模块产生合理的初始辐射场。该研究还使用合理的权重在 Point-NeRF 表示中初始化 MLP,从而显着节省了每个场景的拟合时间。
此外,除了使用完整的生成模块外,该研究的 pIPeline 还支持使用从其他方法(如 COLMAP [44])进行点云重建,其中模型(不包括 MVS 网络)仍然可以为每个点提供有意义的初始神经特征。
实验
该研究首先在 DTU 测试集上对模型进行评估,比较内容包括 PixelNeRF 、IBRNet 、MVSNeRF 和 NeRF ,并用 10k 迭代微调所有方法以进行比较。具体结果如下:
表 1 为不同方法定量比较,比较内容包括 PSNR, SSIM, LPIPS,图 6 为渲染结果。由结果可得,在 10k 次迭代之后,SSIM 和 LPIPS 达到最佳,分别为 0.957 和 0.117,优于 MVSNeRF 和 NeRF 结果。IBRNet 生成的 PSNR 结果稍好一些为 31.35,但 Point-NeRF 可以恢复更精确的纹理细节和高光,如图 6 所示。
另一方面,IBRNet 的微调成本也更高,相同的迭代次数,比 Point-NeRF 微调多花 1 小时,也就是 5 倍的时间。这是因为 IBRNet 依赖大型的全局 CNN,而 Point-NeRF 利用局部点特征以及 MLP 更容易优化。更重要的是,基于点的表示位于实际场景表面附近,从而避免了在空场景中采样射线点(Ray points),从而实现高效的逐场景优化。


虽然 IBRNet 中更复杂的特征提取器可以提高质量,但它会增加内存使用,影响训练效率。更重要的是,Point-NeRF 生成网络已经提供了高质量的初始辐射场,以支持高效优化。该研究发现,即使经过 2 Min / 1K 的微调迭代,Point-NeRF 也能获得非常高的视觉质量,可与 MVSNeRF 最终的 10k 次迭代结果相媲美,这也证明了 Point-NeRF 方法重建效率的高效性。
虽然 Point-NeRF 是在 DTU 数据集上训练而来,但其可以很好地泛化到新的数据集。该研究展示了在 NeRF synthetic 数据集中,Point-NeRF 与其他 SOTA 方法比较结果,定性结果如图 7 ,定量结果如表 2。
实验结果表明,Point-NeRF_20K 明显优于 IBRNet 结果,具有更好的 PSNR、SSIM 和 LIPIPS;该研究还通过更好的几何和纹理细节实现了高质量渲染,如图 7 所示。
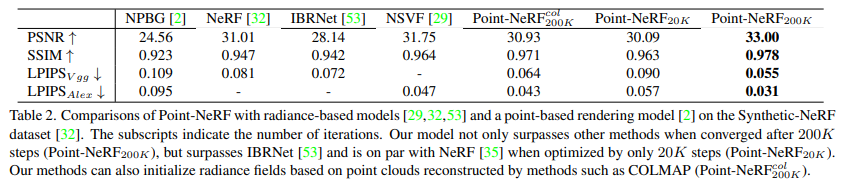

与不同场景的比较:Point-NeRF 在 20K 迭代后,非常接近 NeRF 在 200K 迭代训练后的结果。从视觉上来讲,Point-NeRF 在 20K 迭代后在某些情况下已经有了更好的渲染效果,例如图 7 中的 FicUS 场景(第四行)。Point-NeRF_20K 只用了 40 分钟进行优化,而 NeRF 需要 20 + 小时,两者相比,Point-NeRF 快了近 30 倍,但 NSVF 的优化效果只比 Point-NeRF 的 40 分钟效果略好。如图 7 所示,Point-NeRF 200K 结果包含最多的几何和纹理细节,而且,该方法是唯一可以完全恢复的方法。