
神经辐射场(NeRF)这一技术能够创建人工智能生成的三维环境和三维物体。
但这种新的图像合成技术需要大量的训练时间,并且缺乏实现实时、高度响应接口的实现。
然而,企业和学术界之为这一挑战提供了新的思路&Mdash;&Mdash;新视图合成 (NVS)。
近日,一篇题为NeuRal LuMigRaph RendeRing的研究论文声称,它对现有的2个数量级图像进行了改进,展示了通过机器学习管道实现实时 CG 渲染的几个步骤。

与以前的方法相比,神经光图渲染提供了更好的混合伪像分辨率,并改进了遮挡的处理。

除了斯坦福大学和全息显示技术公司的研究人员,这篇论文的贡献者还包括谷歌首席机器学习架构师、 Adobe 的计算机科学家,以及 SToryfile 的首席技术官。
体积捕获的原理是拍摄主题的静态图像或视频,并使用机器学习来「填充」原始文档未涵盖的观点的想法。
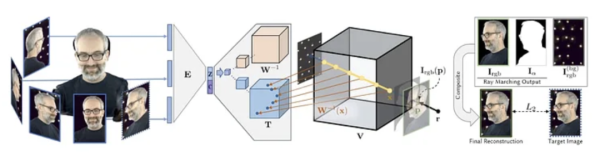
上图取自 FACEbook AI 的 2019 AI 研究 ,可以看出体积捕获的四个阶段:
1 多个摄像机获取图像/画面;
2 编码器/解码器架构(或其他架构)计算并连接视图的相关性;
3 射线行进算法计算空间中每个点的体素(或其他 XYZ 空间几何单位) ;
4 训练合成一个完整的实体,可以实时操作。
到目前为止,正是这种数据量大的训练阶段使得新视图合成超出了实时或高响应捕获的范畴。
事实上,新视图合成制作了一个完整3D地图的体积空间,意味着它是把这些点缝合到一个传统的计算机生成的网格,有效地捕捉和连接一个实时CGI 角色。
使用 NeRF 的方法依靠点云和深度图在捕获设备的稀疏视点之间生成插值:

尽管 NeRF 能够计算网格,但大多数并不使用它来生成体积场景。
相比之下,魏茨曼科学研究所在2020年10月发布的隐式可区分渲染(IDR)方法,取决于利用从捕获数组自动生成的3D网格信息。

虽然 NeRF 缺乏 IDR 的形状估计能力,IDR无法比拟的neRf的图像质量,而且两者都需要大量的资源来训练和整理。
NLR的CUStoM相机装置具有16台GoPRo HERO7和6台中央Back-Bone H7Pro相机。对于实时渲染,它们的最低运行速度为60fps。

相反,神经光图渲染利用 SIREN (正弦表示网络)将每种方法的优点整合到它自己的框架中,目的是生成直接可用于现有实时图形管道的输出。
在过去一年中,SIREN 已被用于类似场景,现在是图像合成社区中业余爱好者 Colabs 的一个流行的 API 调用。
然而,NLR 的创新是将 SIREN 应用于二维多视图图像监控。
从阵列图像中提取 CG 网格后,通过 OpenGL 对网格进行栅格化,将网格的顶点位置映射到适当的像素点,然后计算各种贡献图的融合。
结果得到的网格比 NeRF 的网格更加具有代表性,需要更少的计算,并且不会将过多的细节应用到不能从中受益的区域(如光滑的面部皮肤) :

另一方面,NLR 还没有任何动态照明或重点照明的能力,输出仅限于阴影地图和其他照明时获得的信息。研究人员打算在未来的工作中解决这个问题。
此外,论文承认由 NLR 生成的图形并不像一些替代方法那样精确,或者前面提到的魏茨曼科学研究。
利用神经网络从一系列有限的照片中创建3D实体的想法早于 NeRF,而相关研究可以追溯到2007年或更早。
在2019年,FACEbook 的人工智能研究部门发表了一篇开创性的研究论文,该论文首次为基于机器学习的体积捕获生成的合成人启用了响应界面。
