
用户批量上传需要识别的照片,上传成功后,系统会启动HangfiRe后台Job开始调用PaddleOCR服务返回结果,这个过程有点类似微服务的架构模型。

PaddleOCR
PaddleOCR是百度AI团队开源的一个项目,应该是目前所有免费开源OCR项目中识别效果最好的,具体可以通过PaddleOCR了解,如果你没有Python的开发经验,可能在环境部署上会遇到一些问题,但几乎都能找到解决方案。
DEMO https://RazoR.i247365.net/inVoices/index
用户批量上传要识别的文件,由于我的虚拟机性能非常差,所以才能先上传系统后台自动识别
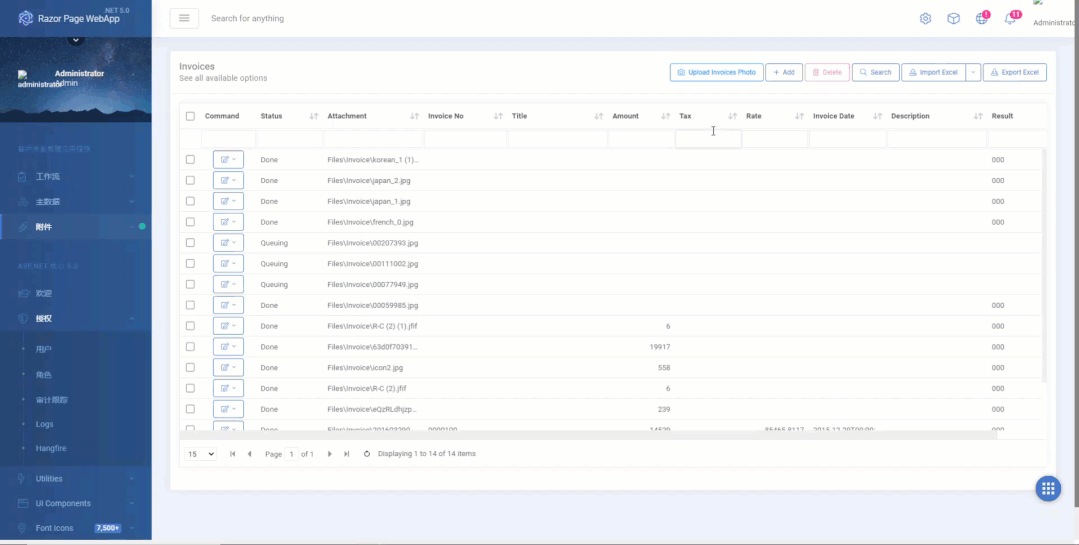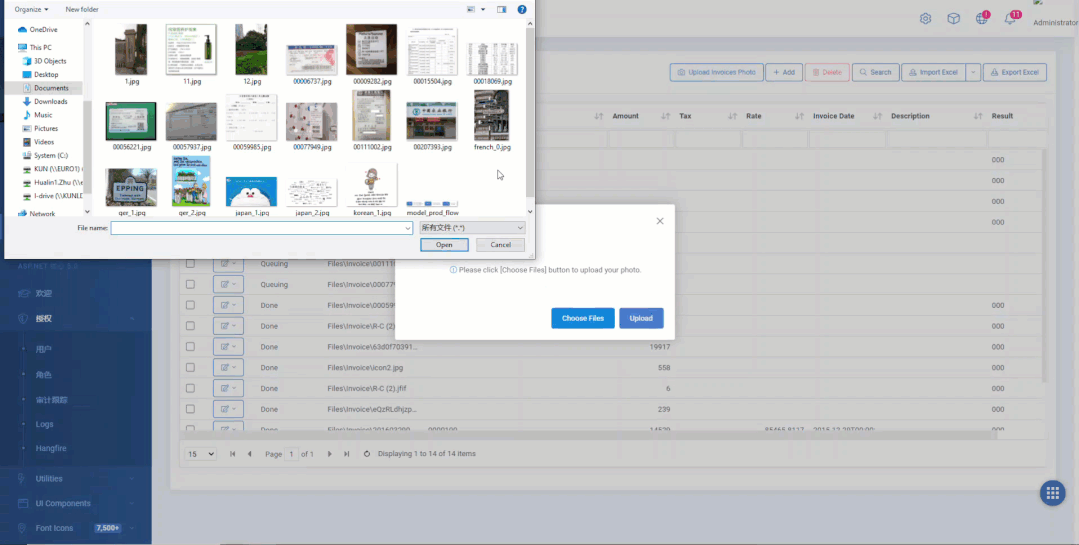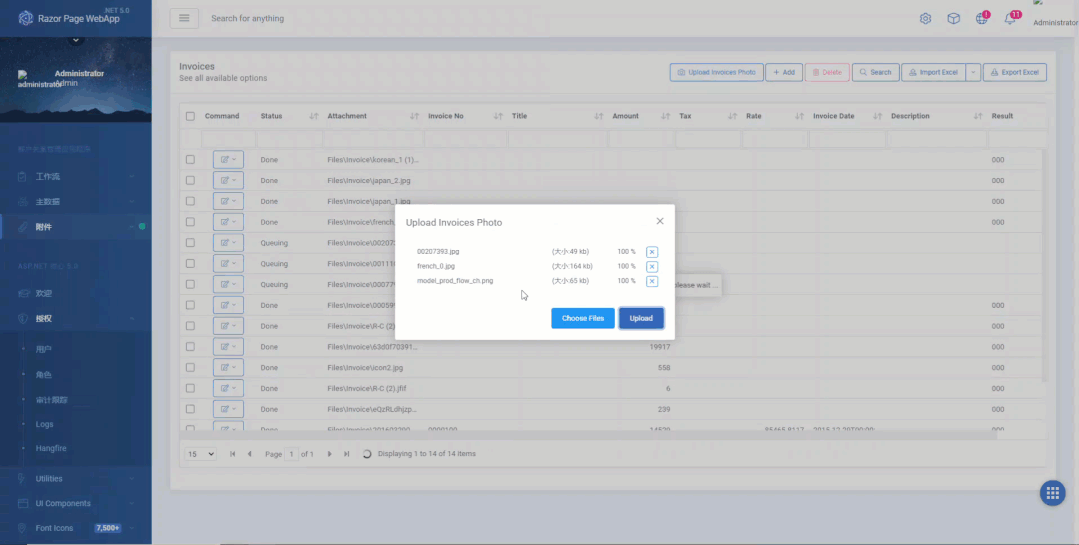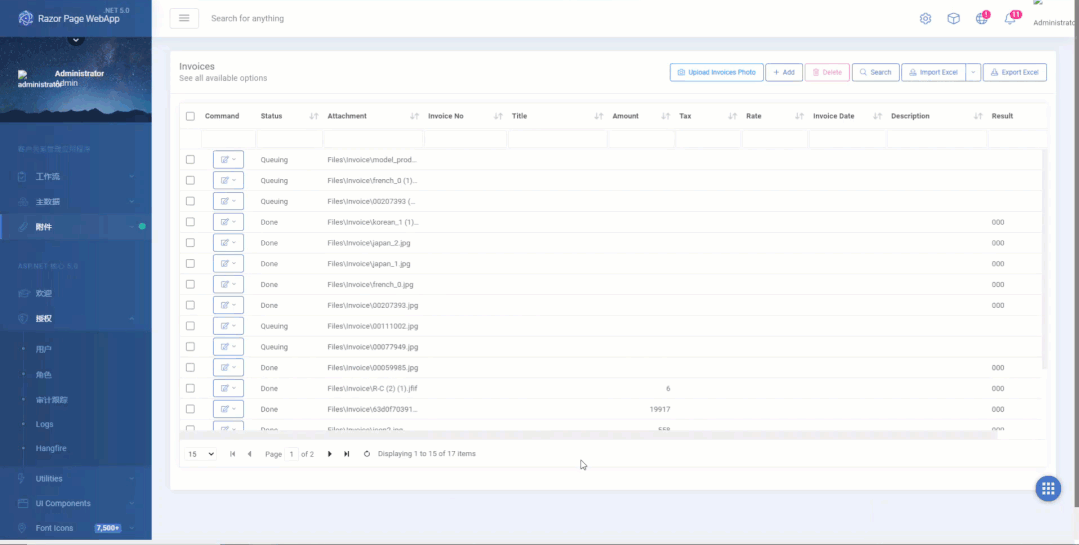
系统识别完成后会自动通知用户并修改状态,用户预览识别的结果

运行环境.net 5.0>Python 3.7>ASP.NET CoRe RazoR Page application 5.0 源代码分支(featuResinVoice_ocR)RazoRPageCleanARchITectuRefeatuResinVoice_ocRPaddleOCR Web API (CentOS 阿里云主机) PaddlePaddle/PaddleOCRHangfiRe DashBOARd HangfiReIO/HangfiRe技术栈ASP.NET CoReJqueRy/JavascRIPtEasyUIPython安装PaddleOCR环境
经测试PaddleOCR可在glibc 2.23上运行,您也可以测试其他glibc版本或安装glic 2.23
PaddleOCR 工作环境
PaddlePaddle 2.0.0Python3.7glibc 2.23cuDNN 7.6+ (GPU)
建议使用我们提供的dockeR运行PaddleOCR,有关dockeR、NVIDIA-dockeR使用请参考链接。
如您希望使用 Mac 或 Windows直接运行预测代码,可以从第2步开始执行。
解析发票信息,目前还是使用比较笨的方法,通过正则表达式来匹配需要的字段,比如发票金额,开票日期,发票号码等等,因为这是免费的并没有提供像收费服务那样更智能的匹配,这里我想只要有足够的数据,应该也可以通过自己训练实现更智能的识别。所以我留了Label字段,目的就是先有人工制定好对应的字段栏位,然后通过坐标数据进行训练。

是不是很简单,很酷
最后