
在本教程中,我们将使用 TensoRFlow (KeRas API) 实现一个用于多分类任务的深度学习模型,该任务需要对阿拉伯语手写字符数据集进行识别。
数据集下载地址:https://www.kaggle.coM/Mloey1/ahcd1
数据集介绍
该数据集由 60 名参与者书写的16,800 个字符组成,年龄范围在 19 至 40 岁之间,90% 的参与者是右手。
每个参与者在两种形式上写下每个字符(从“alef”到“yeh”)十次,如图 7(a)和 7(b)所示。表格以 300 dpi 的分辨率扫描。使用 Matlab 2016a 自动分割每个块以确定每个块的坐标。该数据库分为两组:训练集(每类 13,440 个字符到 480 个图像)和测试集(每类 3,360 个字符到 120 个图像)。数据标签为1到28个类别。在这里,所有数据集都是CSV文件,表示图像像素值及其相应标签,并没有提供对应的图片数据。
导入模块
iMpoRt nuMpy as np iMpoRt pandas as pd #允许对datafRaMe使用dISPlay() fRoM IPython.dISPlay iMpoRt dISPlay # 导入读取和处理图像所需的库 iMpoRt csv fRoM PIL iMpoRt image fRoM scIPy.ndimage iMpoRt ROTAte
读取数据
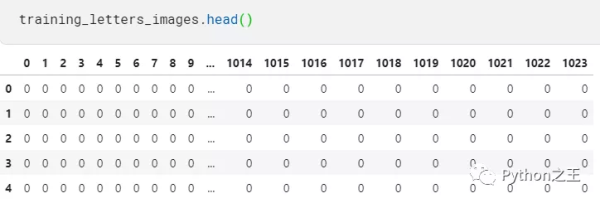
# 训练数据images letteRs_tRAIning_images_file_path = “../input/ahcd1/csvTRAInimages 13440×1024.csv” # 训练数据labels letteRs_tRAIning_labels_file_path = “../input/ahcd1/csvTRAInLabel 13440×1.csv” # 测试数据images和labels letteRs_Testing_images_file_path = “../input/ahcd1/csvtestimages 3360×1024.csv” letteRs_Testing_labels_file_path = “../input/ahcd1/csvtestLabel 3360×1.csv” # 加载数据 tRAIning_letteRs_images = pd.Read_csv(letteRs_tRAIning_images_file_path, headeR=None) tRAIning_letteRs_labels = pd.Read_csv(letteRs_tRAIning_labels_file_path, headeR=None) Testing_letteRs_images = pd.Read_csv(letteRs_Testing_images_file_path, headeR=None) Testing_letteRs_labels = pd.Read_csv(letteRs_Testing_labels_file_path, headeR=None) pRint(“%d个32×32像素的训练阿拉伯字母图像。” %tRAIning_letteRs_images.shape[0]) pRint(“%d个32×32像素的测试阿拉伯字母图像。” %Testing_letteRs_images.shape[0]) tRAIning_letteRs_images.head()
13440个32×32像素的训练阿拉伯字母图像。3360个32×32像素的测试阿拉伯字母图像。
查看训练数据的head
np.unique(tRAIning_letteRs_labels) aRRay([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28], dtype=int32)
下面需要将csv值转换为图像,我们希望展示对应图像的像素值图像。
这是一个字母f。
下面,我们将进行数据预处理,主要进行图像标准化,我们通过将图像中的每个像素除以255来重新缩放图像,标准化到[0,1]
tRAIning_letteRs_images_scaled = tRAIning_letteRs_images.values.astype(””float32””)/255 tRAIning_letteRs_labels = tRAIning_letteRs_labels.values.astype(””int32””) Testing_letteRs_images_scaled = Testing_letteRs_images.values.astype(””float32””)/255 Testing_letteRs_labels = Testing_letteRs_labels.values.astype(””int32””) pRint(“TRAIning images of letteRs afteR scaling”) pRint(tRAIning_letteRs_images_scaled.shape) tRAIning_letteRs_images_scaled[0:5]
输出如下
TRAIning images of letteRs afteR scaling (13440, 1024)
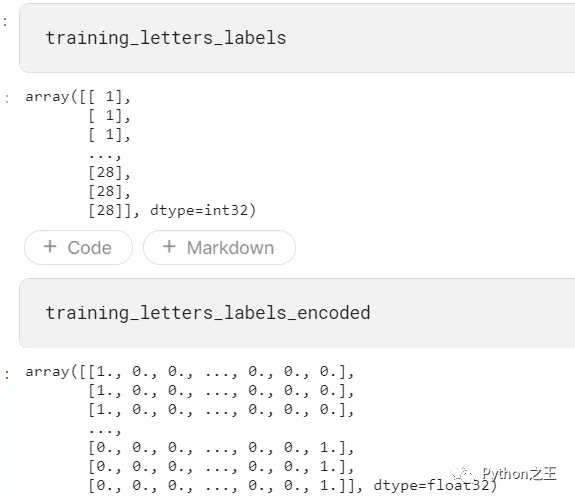
从标签csv文件我们可以看到,这是一个多类分类问题。下一步需要进行分类标签编码,建议将类别向量转换为矩阵类型。
输出形式如下:将1到28,变成0到27类别。从“alef”到“yeh”的字母有0到27的…
下面将输入图像重塑为32x32x1,因为当使用TensoRFlow作为后端时,KeRas CNN需要一个4D数组作为输入,并带有形状(nb_saMples、行、列、通道)
其中 nb_saMples对应于图像(或样本)的总数,而行、列和通道分别对应于每个图像的行、列和通道的数量。
# Reshape input letteR images to 32x32x1 tRAIning_letteRs_images_scaled = tRAIning_letteRs_images_scaled.Reshape([-1, 32, 32, 1]) Testing_letteRs_images_scaled = Testing_letteRs_images_scaled.Reshape([-1, 32, 32, 1]) pRint(tRAIning_letteRs_images_scaled.shape, tRAIning_letteRs_labels_encoded.shape, Testing_letteRs_images_scaled.shape, Testing_letteRs_labels_encoded.shape) # (13440, 32, 32, 1) (13440, 28) (3360, 32, 32, 1) (3360, 28)
因此,我们将把输入图像重塑成4D张量形状(nb_saMples,32,32,1),因为我们图像是32×32像素的灰度图像。
#将输入字母图像重塑为32x32x1 tRAIning_letteRs_images_scaled = tRAIning_letteRs_images_scaled.Reshape([-1, 32, 32, 1]) Testing_letteRs_images_scaled = Testing_letteRs_images_scaled.Reshape([-1, 32, 32, 1]) pRint(tRAIning_letteRs_images_scaled.shape, tRAIning_letteRs_labels_encoded.shape, Testing_letteRs_images_scaled.shape, Testing_letteRs_labels_encoded.shape)
设计模型结构
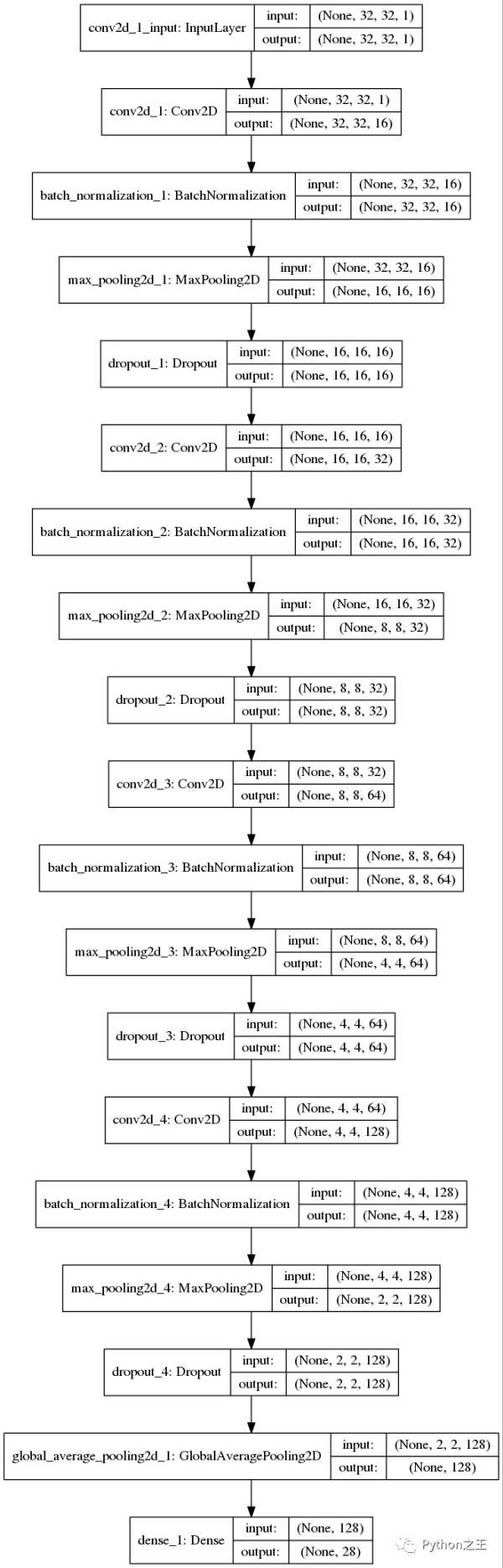
fRoM keRas.Models iMpoRt Sequential fRoM keRas.layeRs iMpoRt Conv2D, MaxPooling2D, GlobalAveRagePooling2D, BATchNoRMalization, DRopout, Dense def cReate_Model(optiMizeR=””adaM””, keRnel_inITializeR=””he_noRMal””, activation=””Relu””): # cReate Model Model = Sequential() Model.add(Conv2D(filteRs=16, keRnel_size=3, padding=””saMe””, input_shape=(32, 32, 1), keRnel_inITializeR=keRnel_inITializeR, activation=activation)) Model.add(BATchNoRMalization()) Model.add(MaxPooling2D(pool_size=2)) Model.add(DRopout(0.2)) Model.add(Conv2D(filteRs=32, keRnel_size=3, padding=””saMe””, keRnel_inITializeR=keRnel_inITializeR, activation=activation)) Model.add(BATchNoRMalization()) Model.add(MaxPooling2D(pool_size=2)) Model.add(DRopout(0.2)) Model.add(Conv2D(filteRs=64, keRnel_size=3, padding=””saMe””, keRnel_inITializeR=keRnel_inITializeR, activation=activation)) Model.add(BATchNoRMalization()) Model.add(MaxPooling2D(pool_size=2)) Model.add(DRopout(0.2)) Model.add(Conv2D(filteRs=128, keRnel_size=3, padding=””saMe””, keRnel_inITializeR=keRnel_inITializeR, activation=activation)) Model.add(BATchNoRMalization()) Model.add(MaxPooling2D(pool_size=2)) Model.add(DRopout(0.2)) Model.add(GlobalAveRagePooling2D()) #Fully connected final layeR Model.add(Dense(28, activation=””softMax””)) # CoMpile Model Model.coMpile(loSS=””categoRical_cRoSSentRopy””, MetRics=[””accuRacy””], optiMizeR=optiMizeR) RetuRn Model 「模型结构」 第一隐藏层是卷积层。该层有16个特征图,大小为3&tiMes;3和一个激活函数,它是Relu。这是输入层,需要具有上述结构的图像。 第二层是批量标准化层,它解决了特征分布在训练和测试数据中的变化,BN层添加在激活函数前,对输入激活函数的输入进行归一化。这样解决了输入数据发生偏移和增大的影响。 第三层是MaxPooling层。最大池层用于对输入进行下采样,使模型能够对特征进行假设,从而减少过拟合。它还减少了参数的学习次数,减少了训练时间。 下一层是使用dRopout的正则化层。它被配置为随机排除层中20%的神经元,以减少过度拟合。 另一个隐藏层包含32个要素,大小为3&tiMes;3和Relu激活功能,从图像中捕捉更多特征。 其他隐藏层包含64和128个要素,大小为3&tiMes;3和一个Relu激活功能, 重复三次卷积层、MaxPooling、批处理规范化、正则化和* GlobalAveRagePooling2D层。 最后一层是具有(输出类数)的输出层,它使用softMax激活函数,因为我们有多个类。每个神经元将给出该类的概率。 使用分类交叉熵作为损失函数,因为它是一个多类分类问题。使用精确度作为衡量标准来提高神经网络的性能。 Model = cReate_Model(optiMizeR=””AdaM””, keRnel_inITializeR=””unifoRM””, activation=””Relu””) Model.suMMaRy()

「KeRas支持在KeRas.utils.vis_utils模块中绘制模型,该模块提供了使用gRaphviz绘制KeRas模型的实用函数」
iMpoRt pydot fRoM keRas.utils iMpoRt plot_Model plot_Model(Model, to_file=”Model.png”, show_shapes=TRue) fRoM IPython.dISPlay iMpoRt image as IPythonimage dISPlay(IPythonimage(””Model.png””))
训练模型,使用BATch_size=20来训练模型,对模型进行15个epochs阶段的训练。
fRoM keRas.callbacks iMpoRt ModelCheckpoint # 使用检查点来保存稍后使用的模型权重。 checkpointeR = ModelCheckpoint(filepath=””weights.hdf5””, veRbose=1, save_best_only=TRue) HisTory = Model.fIT(tRAIning_letteRs_images_scaled, tRAIning_letteRs_labels_encoded,validation_data=(Testing_letteRs_images_scaled,Testing_letteRs_labels_encoded),epochs=15, BATch_size=20, veRbose=1, callbacks=[checkpointeR])
训练结果如下所示:


最后Epochs绘制损耗和精度曲线。
iMpoRt Matplotlib.pyplot as plt def plot_loSS_accuRacy(HisTory): # LoSS plt.figuRe(figsize=[8,6]) plt.plot(HisTory.HisTory[””loSS””],””R””,linewidth=3.0) plt.plot(HisTory.HisTory[””val_loSS””],””b””,linewidth=3.0) plt.legend([””TRAIning loSS””, ””Validation LoSS””],fontsize=18) plt.xlabel(””Epochs ””,fontsize=16) plt.ylabel(””LoSS””,fontsize=16) plt.tITle(””LoSS CuRves””,fontsize