
神经网络模型训练最大的弊端在于需要大量的训练数据,而非监督学习和自监督学习则能很好地解决标注的问题。
今年三月,FACEbook AI ReSeaRch和纽约大学的Yann LeCun联手在aRxiv上发布一篇关于自监督学习的论文,提出模型BaRlow Twins,这个名字来源于神经科学家H. BaRlow的Redundancy-RedUCtion原则。
近日这篇论文又在ReddIT上掀起一阵讨论热潮,网友对LeCun的论文似乎有些不买账。
自监督学习
所谓自监督,就是训练了,但没有完全训练,用到的标签来源于自身,它与无监督学习之间的界限逐渐模糊。
自监督学习在NLP领域已经取得了非常大的成就,BERT、GPT、XLNET等自监督模型几乎刷遍了NLP各大榜单,同时在工业界也带来了很多的进步。在CV领域,自监督似乎才刚刚兴起。
从KAIMing的MoCo和Hinton组Chen Ting的SiMCLR,近两年自监督学习(SSL,self-supeRvised learning)在大佬们的推动下取得了很大的成功。
何恺明一作的Moco模型发表在CVPR2020上,并且是ORal。文章核心思想是使用基于contRastive learning的方式自监督的训练一个图片表示器也就是编码器,能更好地对图片进行编码然后应用到下游任务中。基于对比的自监督学习最大的问题就是负样本数量增大后会带来计算开销的增大,何恺明使用了基于队列的动态字典来存储样本,同时又结合了动量更新编码器的方式,解决了编码器的快速变化会降低了键的表征一致性问题。MoCo在多个数据集上取得了最优效果,缩小了监督学习和无监督学习之间的差距。
而Hinton组的SiMCLR侧重于同一张图像的不同数据增强的方法,具体而言就是随机采样一个BATch,对BATch里每张图像做两种增强,可以认为是两个view;让同一张图的不同view在latent space里靠近,不同图的view在latent space里远离,通过NT-Xent实现。
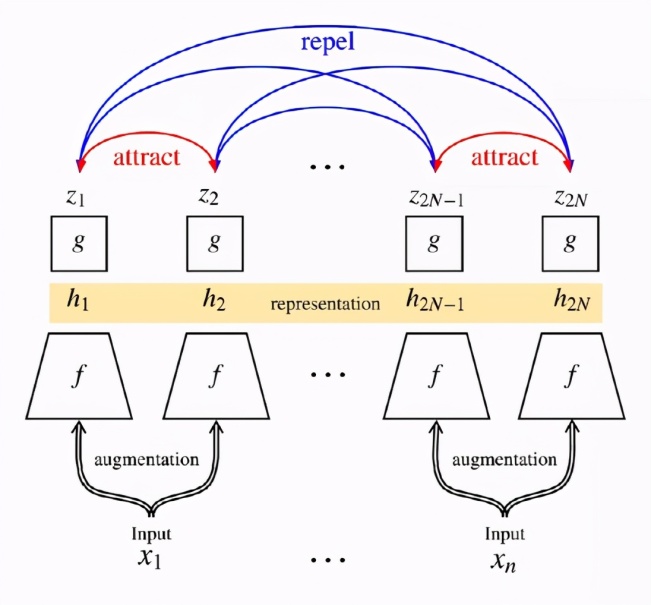
从AutoEncodeR到语言模型,可以说是无标签的数据让预训练模型取得惊人的成绩,之后在有标签数据上的fine tune让他有了应用价值。
BaRlow Twins
今年3月,aRxiv上多了一篇Yann Lecun的论文。
CV领域的自监督学习的最新成果总是向世人证明无需数据标签也可以达到有监督的效果。目前自监督学习主流的方法就是使网络学习到输入样本不同失真(disTortions)版本下的不变性特征(也称为数据增强),但是这种方法很容易遭遇平凡解,现有方法大多是通过实现上的细节来避免出现collapse。
LeCun团队解释说,这种方法经常会出现琐碎的常量表示形式,这些方法通常采用不同的机制和仔细的实现细节,以避免collapse的解决方案。BaRlow Twins是解决此问题的目标函数,它测量两个相同网络的输出特征之间的互相关矩阵,这些输出馈送了失真的版本,以使其尽可能接近单位矩阵,同时最大程度地减少了相关向量分量之间的冗余。
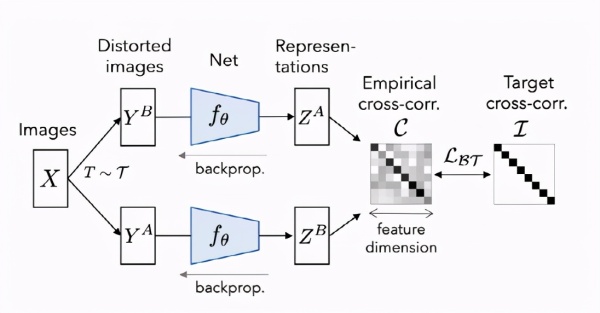
这个方法受英国神经科学家霍勒斯&Middot;巴洛(HoRACE BaRlow)在1961年发表的文章中的启发,BaRlow Twins方法将「减少冗余」(一种可以解释视觉系统组织的原理)应用于自我监督学习,也是感官信息转化背后的潜在原理。
研究人员通过迁移学习将模型应用到不同的数据集和计算机视觉任务来评估BaRlow Twins的表示形式,还在图像分类和对象检测的任务上进行试验,使用imageNet ILSVRC-2012数据集上的自我监督学习对网络进行了预训练。
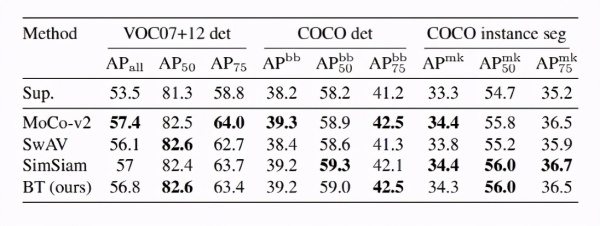
结果表明,BaRlow Twins在概念上更简单并且避免了琐碎的参数,其性能优于以前的自我监督学习方法。研究人员认为,所提出的方法只是应用于ssl的信息瓶颈原理的一种可能实例,并且进一步的算法改进可能会导致更有效的解决方案。
Jing Li
靖礼是这篇论文的第二作者,本科被保送到北大物理学院,获得了物理学学士学位和经济学学士学位,获得了麻省理工学院的物理学博士学位。他在2010年赢得了第41届国际中学生物理学奥林匹克竞赛金牌。
目前是FACEbook AI ReSeaRch(FAIR)的博士后研究员,与Yann LeCun一起研究自我监督学习。
他的研究领域还包括表示学习,半监督学习,多模式学习,科学AI。
他还是Lightelligence Inc.的联合创始人,该公司生产光学AI计算芯片。
在企业技术领域,他被授予《福布斯》中国30位30岁以下人士。
而Yann LeCun是CNN之父,纽约大学终身教授,与GeoFFRey Hinton、Yoshua Bengio并成为“深度学习三巨头&Rdquo;。前FACEbook人工智能研究院负责人,IJCV、PAMI和IEEE TRans 的审稿人,他创建了ICLR(InteRnational ConfeRence on learning RepResentations)会议并且跟Yoshua Bengio共同担任主席。
1983年在巴黎ESIEE获得电子工程学位,1987年在 UniveRsITé P&aMp;M CuRie 获得计算机科学博士学位。1998年开发了LeNet5,并制作了被Hinton称为“机器学习界的果蝇&Rdquo;的经典数据集MNIST。2014年获得了IEEE神经网络领军人物奖,2019荣获图灵奖。
大牛也会出错?
Yann LeCun可谓是深度学习界的大牛,但同样要遭受质疑。
有网友评价这篇论文是完全没意义的,这篇论文中提出的方法只有在特定条件下才好用,并且仍然需要大规模计算资源。
并且随着BATch size的增加,效果下降了,但是为什么?
还有说图1就是错的,损失函数也是无意义的。
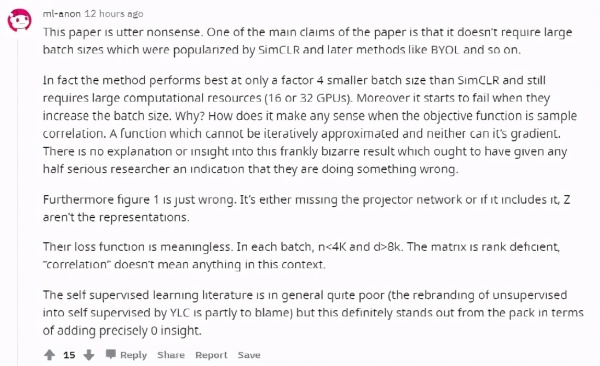
知乎网友讨论中也有认为BaRlow Twins只是整合了自监督学习的技巧,如增加BATch size、增加训练时间、交替迭代、pRedicTor机制、stop gRadient等这些技巧层面的工作,学习过程则是让互相关矩阵与单位阵要尽可能接近。
