
AI面部识别领域又开辟新业务了?
这次,是鉴别二战时期老照片里的人脸图像。
近日,来自谷歌的一名软件工程师Daniel Patt 研发了一项名为N2N的 AI人脸识别技术,它可识别二战前欧洲和大屠杀时期的照片,并将他们与现代的人们联系起来。

用AI寻找失散多年的亲人
2016年,帕特在参观华沙波兰裔犹太人纪念馆时,萌生了一个想法。
这一张张陌生的脸庞,会不会与自己存在血缘的联系?
他的祖父母/外祖父母中有三位是来自波兰的大屠杀幸存者,他想帮助祖母找到被纳粹杀害的家人的照片。
二战时期,由于波兰裔犹太人众多,且被关押在不同集中营,许多都下落不明。
仅仅通过一张发黄的照片,很难辨别其中的人脸是谁,更别提找到自己失落的亲人。

于是,他回到家中,立马把这个想法转化为现实。
该软件最初的设想是通过数据库收集人脸的图像信息,并利用人工智能算法帮助匹配相似度最高的前十个选项。
其中大部分的图像数据来自美国大屠杀纪念馆(The US HolocaUSt MeMoRial MUSeuM),此外还有超过一百万张图像来自全国各地的数据库。
用户只需选择电脑文件中的图像,点击上传,系统便会自动筛选出匹配图最高的前十个选项。
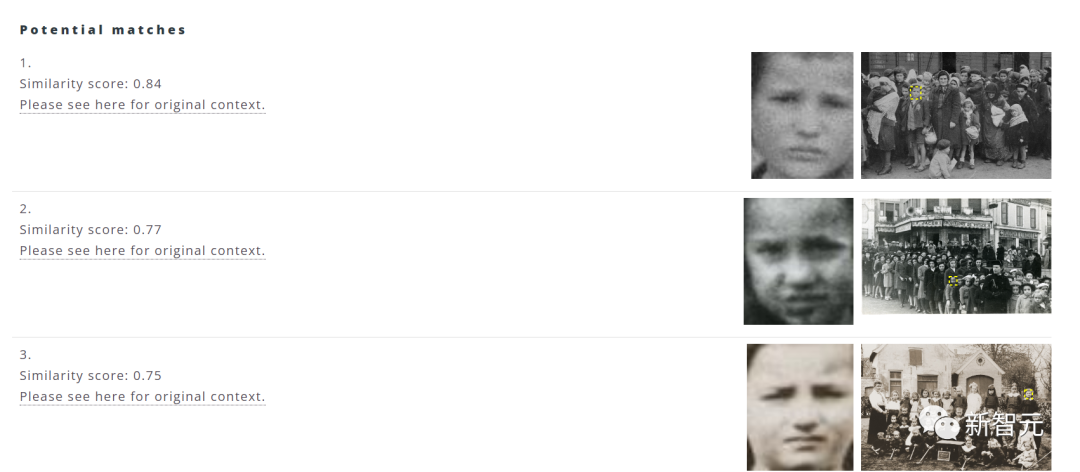
另外,用户还可以点击源地址查看该图片的年份、地点、藏馆等信息。

有个槽点是,如果输入现代的人物图像,检索结果也可能会很离谱。
结果就是这?(黑人问号)
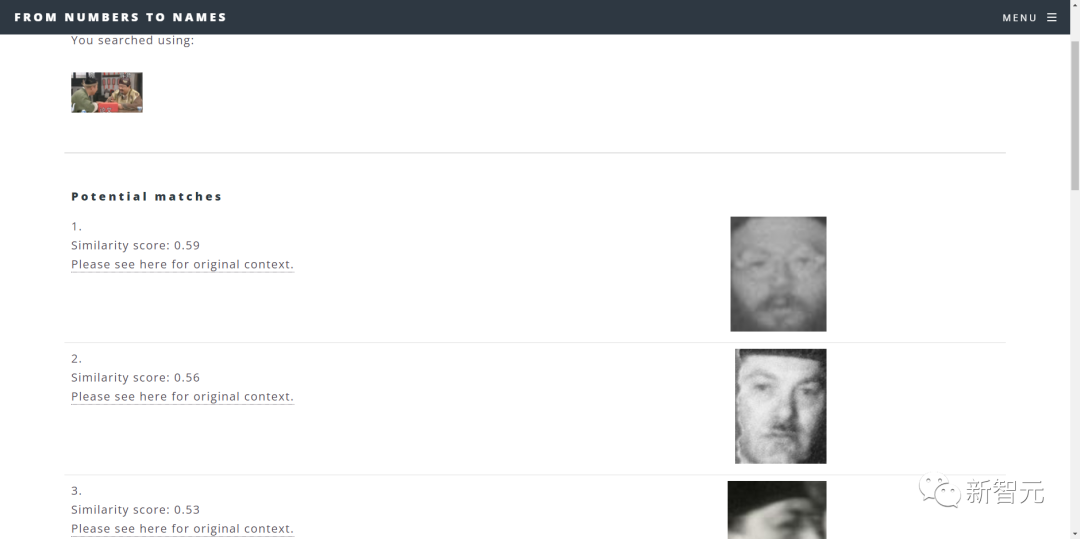
总之就是系统功能还需要完善。
此外,Patt还与谷歌的其他软件工程师和数据科学家团队合作,旨在提高搜索的范围与准确度。
由于脸部识别系统存在隐私泄露的风险,Patt表示,「我们不对身份作出任何评价, 我们只负责用相似度分数呈现结果,并让用户自己去判断」。
AI面部识别技术的发展

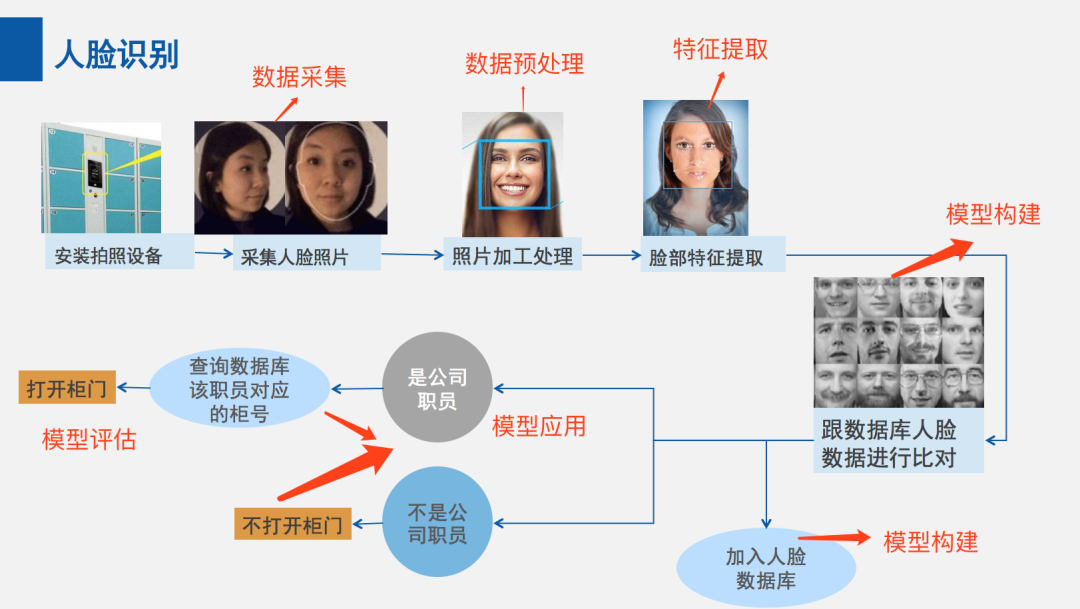
那么这项技术是如何对人脸进行识别的呢?
最初,人脸识别技术还得从「如何判断检测的图像是一张脸」开始。
2001年,计算机视觉研究人员 Paul Viola 和 Michael Jones 提出了一个框架,以高精度实时检测人脸。
这个框架可基于训练模型来理解「什么是人脸,什么不是人脸」。
训练完成后,模型会提取特定特征,然后将这些特征存储在文件中,以便可以将新图像中的特征与之前存储的特征在各个阶段进行比较。
为了帮助确保准确性,算法需要在包含「数十万正负图像的大型数据集」上进行训练,从而提高算法确定图像中是否有人脸及其位置的能力。
如果所研究的图像通过了特征比较的每个阶段,则已检测到人脸并且可以继续操作。
尽管 Viola-Jones 框架在实时应用程序中用于识别人脸精确度很高,但它存在一定的局限性。
例如,如果人脸戴上口罩,或者如果一张脸没有正确定向,则该框架可能无法工作。
为帮助消除 Viola-Jones 框架的缺点并改进人脸检测,他们又开发了其他算法。
如基于区域的卷积神经网络 (R-CNN) 和单镜头检测器 (SSD)来帮助改进流程。
卷积神经网络 (CNN) 是一种用于图像识别和处理的人工神经网络,专门用于处理像素数据。
R-CNN 在 CNN 框架上生成区域提议,以对图像中的对象进行定位和分类。
虽然基于区域提议网络的方法(如 R-CNN)需要两个镜头——一个用于生成区域提议,另一个用于检测每个提议的对象——但 SSD 只需要一个镜头来检测图像中的多个对象。因此,SSD 明显快于 R-CNN。

近年来,深度学习模型驱动的人脸识别技术,其优势显著优于传统的计算机视觉方法。
早期的人脸识别多采用传统机器学习算法,研究关注的焦点更多集中在如何提取更有鉴别力的特征上,以及如何更有效的对齐人脸。
随着研究的深入,传统机器学习算法人脸识别在二维图像上的性能提升逐渐到达瓶颈。
人们开始转而研究视频中的人脸识别问题,或者结合三维模型的方法去进一步提升人脸识别的性能,而少数学者开始研究三维人脸的识别问题。
在最出名的 LFW 公开库上,深度学习算法一举突破了传统机器学习算法在二维图像上人脸识别性能的瓶颈,首次将识别率提升到了 97% 以上。
即利用「CNN 网络建立的高维模型」 ,直接从输入的人脸图像上提取有效的鉴别特征,直接计算余弦距离来进行人脸识别。
人脸检测已经从基本的计算机视觉技术发展到机器学习 (ML) 的进步,再到日益复杂的人工神经网络 (ANN) 和相关技术,结果是持续的性能改进。
现在,它作为许多关键应用程序的第一步发挥着重要作用——包括面部跟踪、面部分析和面部识别。
二战期间,中国也遭受了战争的创伤,许多当时照片中的人物早已无法辨别。
爷爷奶奶一辈的曾遭受战争创伤的人们,有许多亲人朋友都下落不明。
这项技术的研发或许将帮助人们揭开尘封的岁月,为过去的人们寻找一些慰藉。