
从社交网络到生物信息学,再到机器人学中的导航和规划问题,图在各种现实世界的数据集中普遍存在。
于是乎,人们对专门用于处理图结构数据的图神经网络(GNN)产生了极大的兴趣。
尽管现代GNN在理解图形数据方面取得了巨大的成功,但在有效处理图形数据方面仍然存在一些挑战。
例如,当所考虑的图较大时,计算复杂性就成为一个问题。
相反,在空间域工作的算法避免了昂贵的频谱计算,但为了模拟较长距离的依赖关系,不得不依靠深度GNN架构来实现信号从远处节点的传播,因为单个层只模拟局部的相互作用。
为解决这些问题,谷歌大脑、哥伦比亚大学和牛津大学的研究团队提出了一类新的图神经网络:GRaph KeRnel Attention TRansfoRMeRs(GKATs)。

该团队证明GKAT比SOTA GNN具有更强的表达能力,同时还减少了计算负担。
全新GNN,降低计算复杂度
「是否有可能设计具有密集单个层的 GNN,显式建模图中更长范围的节点到节点关系,从而实现更浅的架构,同时扩展更大的(不一定是稀疏的)图?」
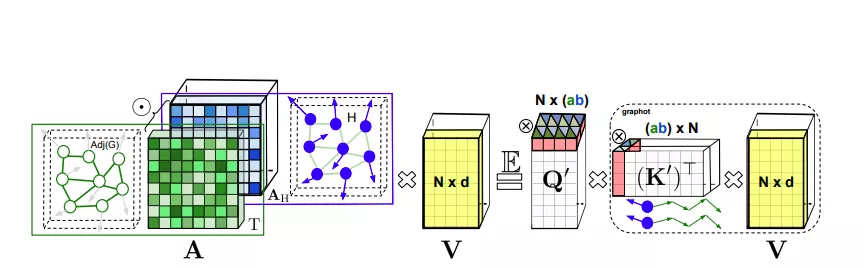
GKATs中可分解的长注意力
GKAT将每一层内的图注意力建模为节点特征向量的核矩阵和图核矩阵的HadaMaRd乘积。
这使GKAT能够利用计算效率高的隐式注意机制,并在单层内对更远距离的依赖项进行建模,从而将其表达能力提升到超越传统GNN的水平。
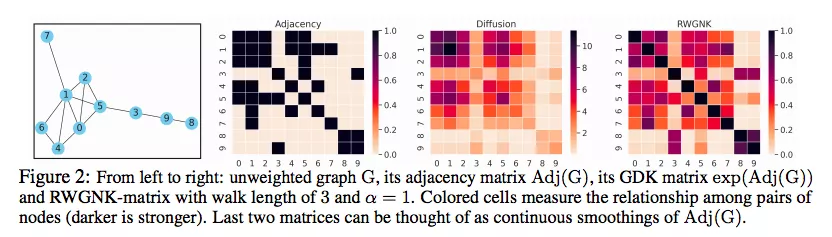
为了在图节点上定义可实现高效映射的表达内核,研究人员采用了一种新颖的随机游走图节点内核 (RWGNKs) 方法,其中两个节点的值作为两个频率向量的点积给出,这些向量记录了图节点中的随机游走。
完整的 GKAT 架构由几个块组成,每个块由注意力层和标准 MLP 层构建而成。
值得注意的是,注意层与输入图的节点数成线性关系而不是二次方,因此与其常规的图注意力对应物相比降低了计算复杂度。
优于9种SOTA GNN
ERdős-Rényi随机图
作者使用了五个二元分类数据集,包括与主题相连的随机ER图(正例)或与模体具有相同平均度的其他较小ER图(负面例子)。
对于每个数据集,构建S个正例和S个负例,其中S=2048。
作者对GKAT、图卷积网络(GCNs)、谱图卷积网络(SGCs)和图注意网络(GATs)进行了测试。
每个顶点的特征向量长度为l=5,并包含其相邻的顶序度数l(如果少于l,则填充0)。
每个模体的数据集被随机分成75%的训练集和25%的验证集。
同时,采用学习率为η=0.001的AdaM优化器,如果验证损失和验证准确率在c=80个连续的epoch中都没有改善,则提前停止训练。
对于模型来说,作者选择使用双层架构,并通过调整使所有模型的规模相当。
在GCN和SGC中,隐层中有h=32个节点。
在SGC中,将每个隐层与2个多项式局部过滤器结合。
在GAT和GKAT中,使用2个注意头,隐层中有h=9个节点。
在GKAT中,使用长度为τ=3的随机游走。

可以看出,GKAT在所有的模体上都优于其他方法。
检测长诱导循环和深度与密度注意力测试
算法需要决定在给定的常数T下,图形是否包含一个长度大于T的诱导循环。
因此,模体本身成为一个全局属性,不能只通过探索一个节点的近邻来检测。
在这个实验中,还要关注「深度与密度」的权衡。
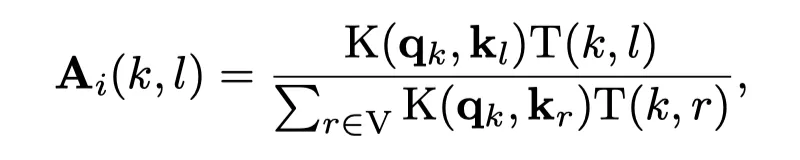
具有密集注意力的浅层神经网络能够对依靠稀疏层的深层网络进行建模,然而代价是每层的额外计算成本。
在实验中需要控制GCN、GAT和SGC的隐层的节点数,以及GAT的每个注意头的数量,使它们的可训练参数总量与双层GKAT相当。
对于GKAT,在第一层应用8个头,在第二层应用1个头,每个头的尺寸为d=4。
最后一层是全连接层,输出维数为o=2,用于二进制分类,并采用τ=6的随机游走长度。
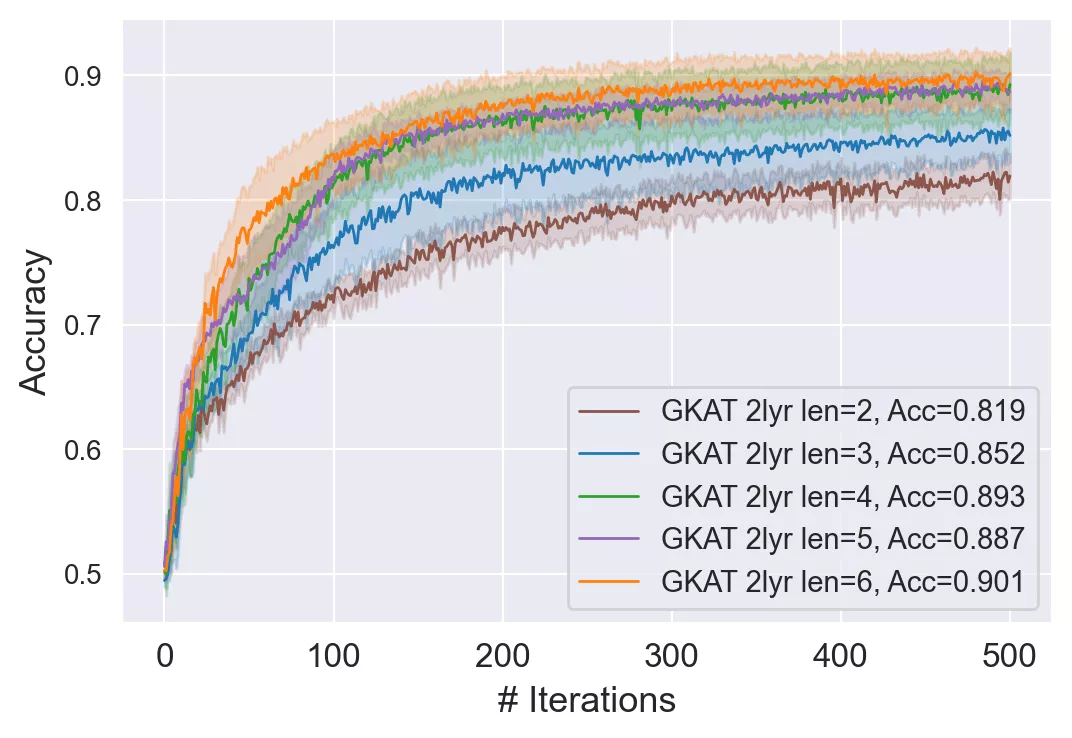
GKAT不同长度的随机游走结果
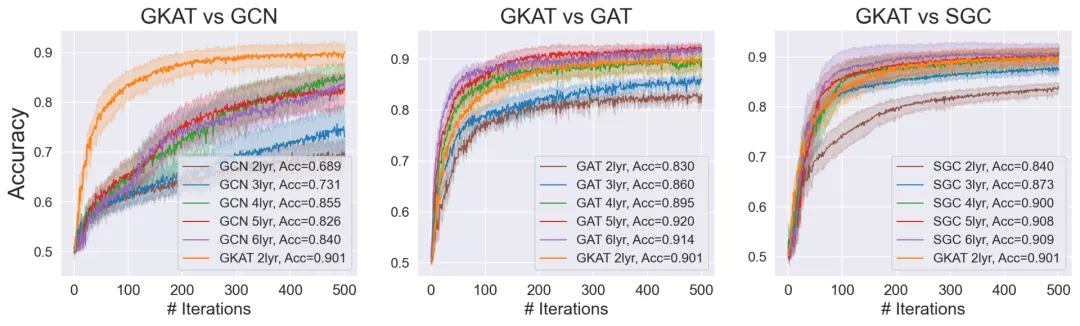
双层GKAT与不同隐层数量(2-6)的GCN、GAT和SGC的比较
可以看到,更浅的GKAT几乎击败了所有的GCN变体以及小于4层的GATs和SGCs。
此外,GKAT在趋势上等同于四层GAT和SGC,但它在训练和运行推理方面更快。
生物信息学任务和社交网络数据测试
作者将GKAT与其他的SOTA GNN方法进行比较,其中包括:DCGNN, DiFFPool, ECC, GRaphSAGE和RWNN 。
对于生物信息学数据集,使用分子指纹(MoleculaR FingeRpRint, MF)方法作为基线。
对于社交网络数据集,使用深度多重集合(DeepMultisets, DM)方法作为基线。
在GKAT配置方面,首先应用了一个有k个头的注意层(一个有待调整的超参数)。
然后是另一个有一个头的注意层,以聚合图上的拓扑信息。
接下来,应用MF方法或DM方法来进一步处理聚合的信息。
每个GKAT层中的随机游走长度τ满足:τ≤4,并且取决于所评估的数据集。
长的随机游走原则上可以捕获更多的信息,但代价是要增加非相关节点。

生物信息学数据集

社交网络数据集
其中,平均图径(每对节点的最长最短路径的平均值)有助于校准游走长度,并在实验中选择节点数与平均节点数最相似的图。
作者在9个标准和公开的生物信息学和社交网络数据集上测试了GKAT的图分类任务。
对于每个数据集,表现最好的方法被加粗显示,第二的由下划线表示。
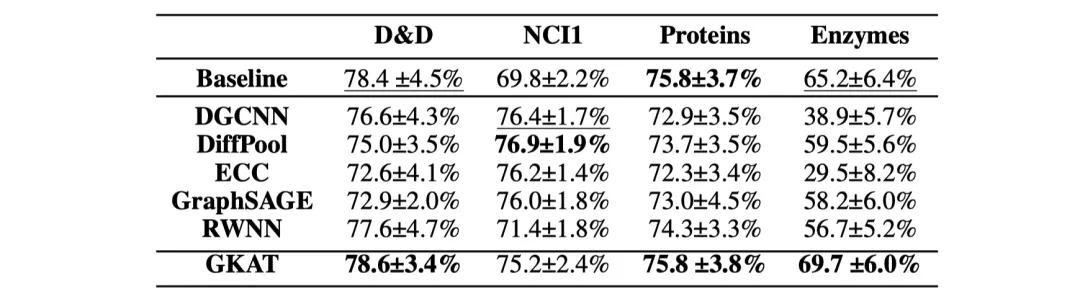
GKAT在生物信息学数据集的四个任务中有三个结果最好
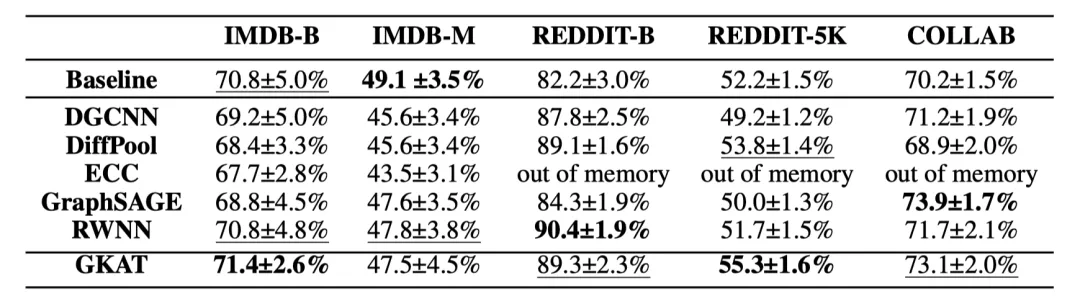
GKAT在社交网络数据集的五个任务中有四个位居前两位
值得注意的是,除了一个生物信息学数据集之外,GKAT是唯一一个在所有的生物信息学数据集上持续优于基线的GNN方法。
GKAT的空间和时间复杂度增益
作者对比了加入可分解注意力机制的GKAT(GKAT+)与GAT在速度和记忆上的改进,以及与常规的GKAT在准确性上的损失。
可以看到,相应的GKAT和GKAT+模型的准确率差距很小。
但是与GAT相比,GKAT+在每个注意层中产生了一致的速度和记忆增益,特别是对于那些来自CITeseeR和PubMed的非常大的图形来说,这种增益是非常可观的。
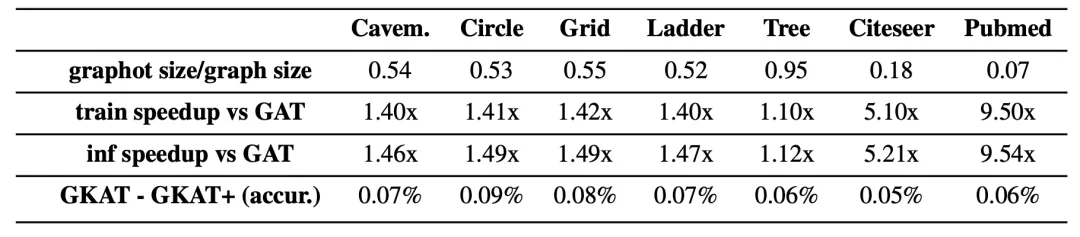
GKAT+在速度和空间复杂度方面的提升
第一行:通过gRaphot对图形进行内存压缩(越低越好)。
第二行和第三行:与GAT相比,每一个注意力层的训练和推理速度分别提高。
第四行:与不应用可分解注意力机制的GKAT相比,准确率的下降。

训练不同网络的时间,均为双层结构
此外,在达到特定精度水平所需的时间方面,常规的GKAT也比相应的模型(GCN、GAT和SGC)快。
总结
作者提出了一个全新的基于注意力的图神经网:GRaph KeRnel Attention TRansfoRMeRs(GKATs):
利用了图核方法和可扩展注意力 在处理图数据方面更具表现力 具有低时间复杂性和内存占用 在广泛的任务上优于其他SOTA模型