

OpenAI前两天发布了最新的GPT-4 Turbo模型:GPT-4 Turbo with Vision,顾名思义,就是具有视觉能力的GPT-4 Turbo模型,够理解图像和视觉内容,并且支持同时处理文字和图像,本文ChatGPT中文网就分享下这个模型的介绍和使用实例。
一、OpenAI发布GPT-4 Turbo with Vision模型
2024年4月10日,OpenAI在X发布声明:GPT-4 Turbo with Vision API已经正式推出。
我们在OpenAI platform中已经可以看到GPT-4 Turbo with Vision模型的介绍,并且GPT-4 Turbo已经指向了这个模型,该模型保留了GPT-4 Turbo的128000令牌窗口,知识截止日期为2023年12月的。
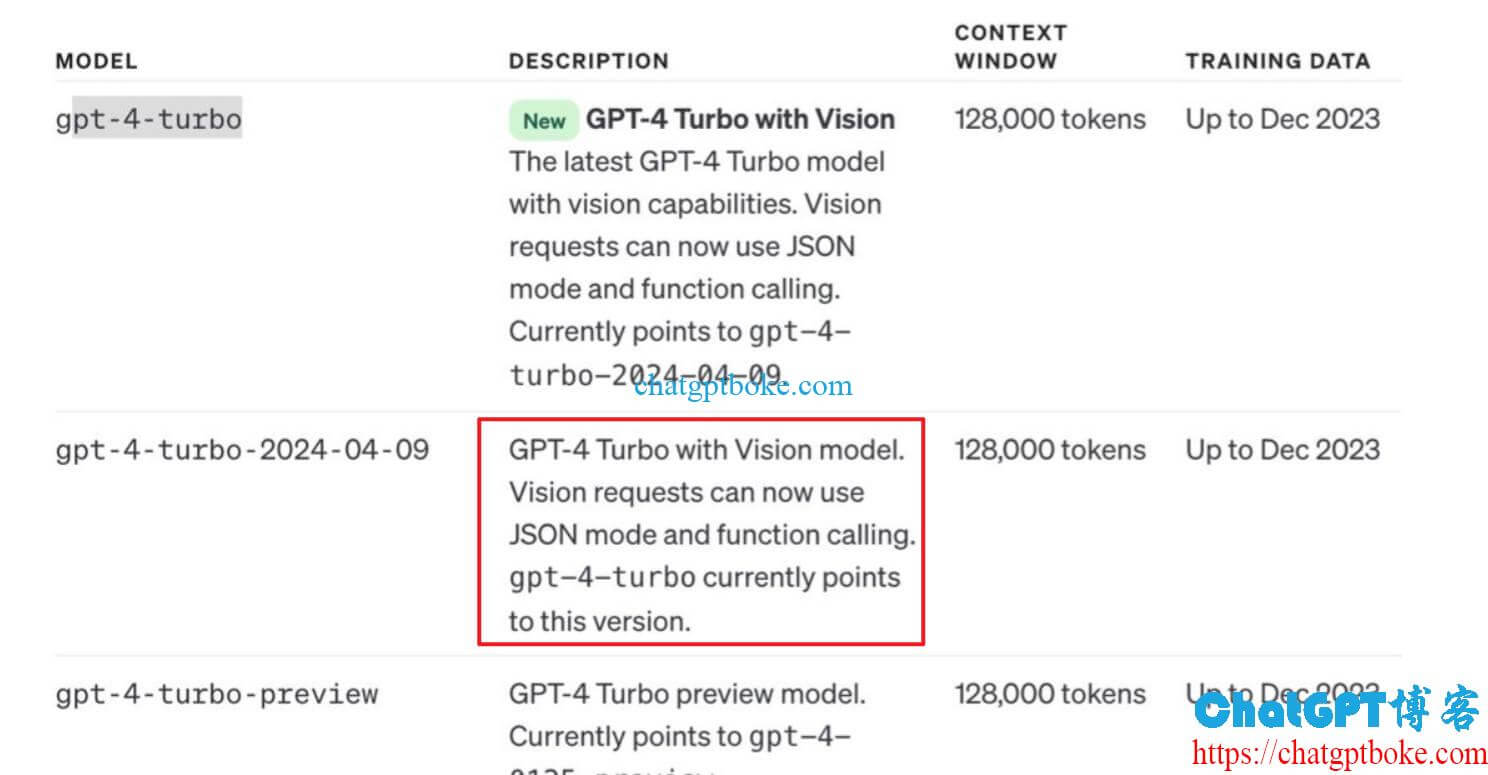
相比于之前的GPT-4 Turbo模型,新推出的GPT-4 Turbo with Vision模型的主要区别就是其视觉能力,它能够理解图像和视觉内容,并且支持同时处理文字和图像,而之前必须要使用不同的模型来处理文字和图像。
二、GPT-4 Turbo with Vision模型使用实例
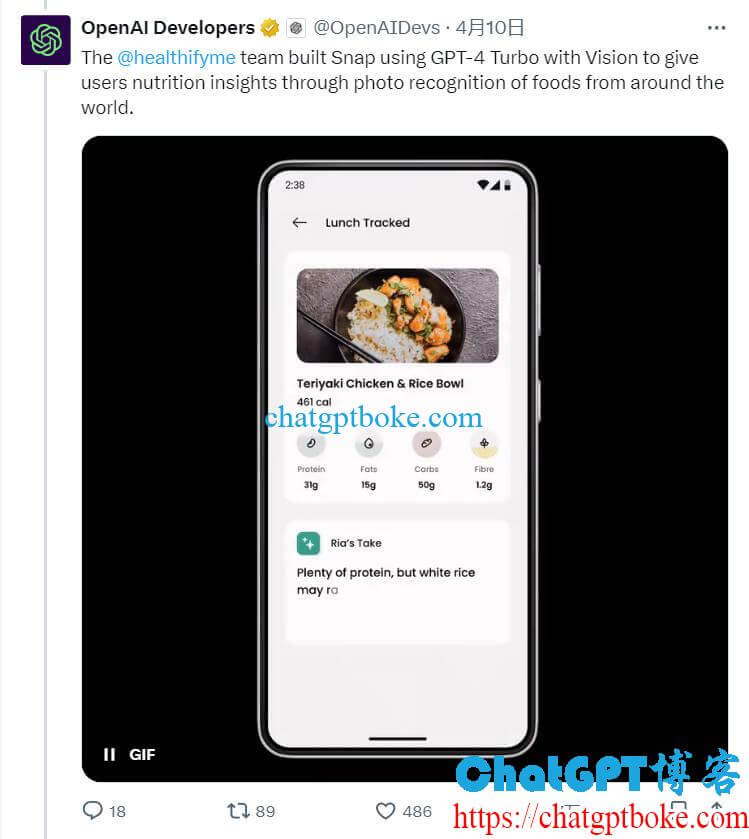
OpenAI在X上分享了一些AI开发者基于GPT-4 Turbo with Vision的开发实例,例如健康和健身应用Healthify使用GPT-4 Turbo with Vision扫描用户餐点照片,并通过图像识别提供营养见解。
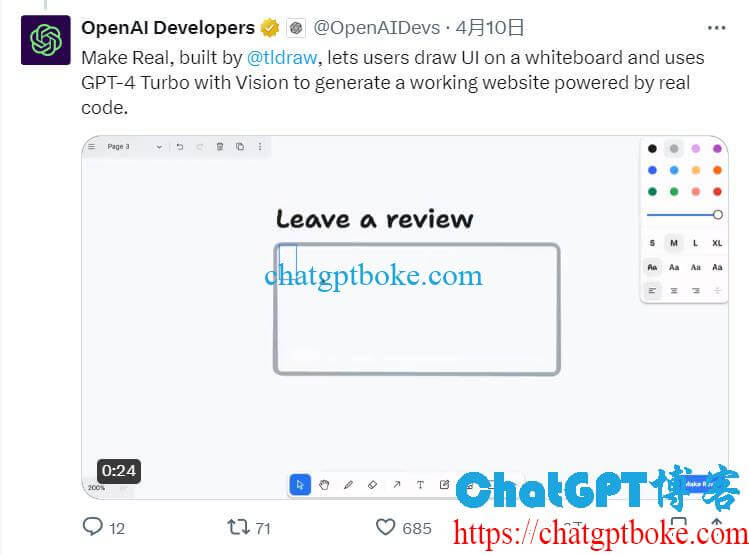
Make Real团队使用GPT-4 Turbo with Vision将用户的绘图转换为可工作的网站。
三、GPT-4 Turbo with Vision模型使用教程
目前GPT-4 Turbo with Vision模型只能通过API调用,ChatGPT用户(包括ChatGPT Plus)都还没有开放,具体的使用教程可以参考OpenAI的分享:https://help.openai.com/en/articles/8555496-gpt-4-vision-api
以上就是最新的GPT-4模型GPT-4 Turbo with Vision模型的介绍。