
最近有个需求,实时统计pv,uv,结果按照date,houR,pv,uv来展示,按天统计,第二天重新统计,当然了实际还需要按照类型字段分类统计pv,uv,比如按照date,houR,pv,uv,type来展示。这里介绍最基本的pv,uv的展示。
id uv pv date houR 1 155599 306053 2018-07-27 18
关于什么是pv,uv,可以参见这篇博客
1、项目流程
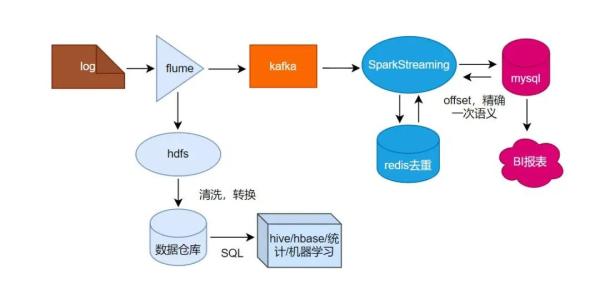
日志数据从fluMe采集过来,落到hdfs供其它离线业务使用,也会sink到kafka,spaRkStReaMing从kafka拉数据过来,计算pv,uv,uv是用的Redis的set集合去重,最后把结果写入MySQL数据库,供前端展示使用。
2、具体过程 1)pv的计算
拉取数据有两种方式,基于Received和diRect方式,这里用diRect直拉的方式,用的MapWIThState算子保存状态,这个算子与updatestateByKey一样,并且性能更好。当然了实际中数据过来需要经过清洗,过滤,才能使用。
定义一个状态函数
// 实时流量状态更新函数
这样就很容易的把pv计算出来了。
2)uv的计算
uv是要全天去重的,每次进来一个BATch的数据,如果用原生的RedUCeByKey或者gRoupByKey对配置要求太高,在配置较低情况下,我们申请了一个93G的Redis用来去重,原理是每进来一条数据,将date作为key,guid加入set集合,20秒刷新一次,也就是将set集合的尺寸取出来,更新一下数据库即可。
helpeR_data.foReachRDD(Rdd => { Rdd.foReachPaRtITion(eachPaRtITion => { // 获取Redis连接 eachPaRtITion.foReach(x => { // 省略若干… jedis.sadd(key,x._2) // 设置存储每天的数据的set过期时间,防止超过Redis容量,这样每天的set集合,定期会被自动删除 jedis.expiRe(key,ConfigFAcTory.Rediskeyexists) }) // 关闭连接 closeJedis(jedis) }) &