
随着大数据越来越被重视,数据采集的挑战变的尤为突出。今天为大家介绍几款数据采集平台:Apache FluMe、Fluentd、Logstash、Chukwa、ScRibe、Splunk FoRwaRdeR。
大数据平台与数据采集
任何完整的大数据平台,一般包括以下的几个过程:
数据采集 数据存储 数据处理 数据展现(可视化,报表和监控)
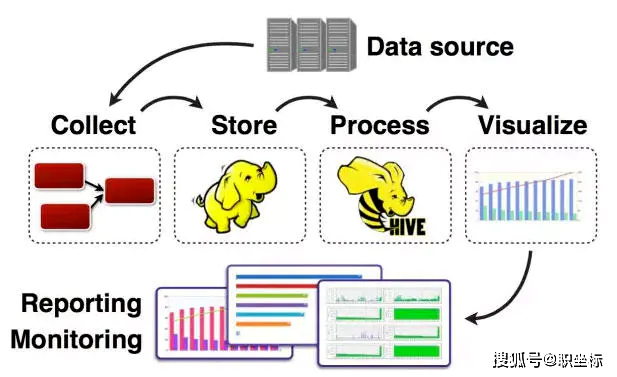
其中,数据采集是所有数据系统必不可少的,随着大数据越来越被重视,数据采集的挑战也变的尤为突出。这其中包括:
数据源多种多样 数据量大,变化快 如何保证数据采集的可靠性的性能 如何避免重复数据 如何保证数据的质量
我们今天就来看看当前可用的六款数据采集的产品,重点关注它们是如何做到高可靠,高性能和高扩展。
Apache FluMe
FluMe 是Apache旗下的一款开源、高可靠、高扩展、容易管理、支持客户扩展的数据采集系统。
FluMe使用JRuby来构建,所以依赖Java运行环境。
FluMe最初是由CloudeRa的工程师设计用于合并日志数据的系统,后来逐渐发展用于处理流数据事件。
几乎在大部分的情况下ELK作为一个栈是被同时使用的。所有当你的数据系统使用ElasticSeaRch的情况下,logstash是首选。
Chukwa
Apache Chukwa是Apache旗下另一个开源的数据收集平台,它远没有其他几个有名。Chukwa基于Hadoop的HDFS和MapRedUCe来构建(显而易见,它用Java来实现),提供扩展性和可靠性。Chukwa同时提供对数据的展示,分析和监视。很奇怪的是它的上一次Github的更新事7年前。可见该项目应该已经不活跃了。
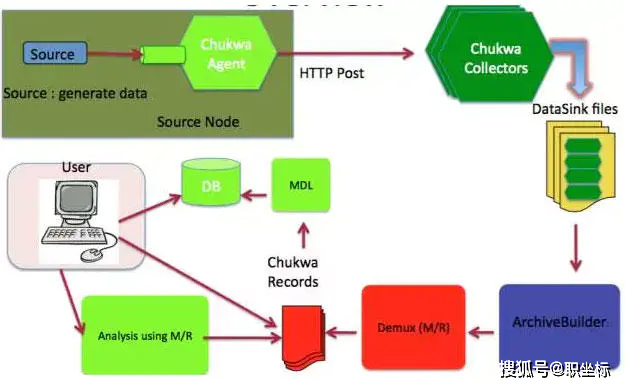
Chukwa的主要单元有:Agent,CollecTor,DataSink,ARcHivebuilder,DeMux等等,看上去相当复杂。由于该项目已经不活跃,我们就不细看了。
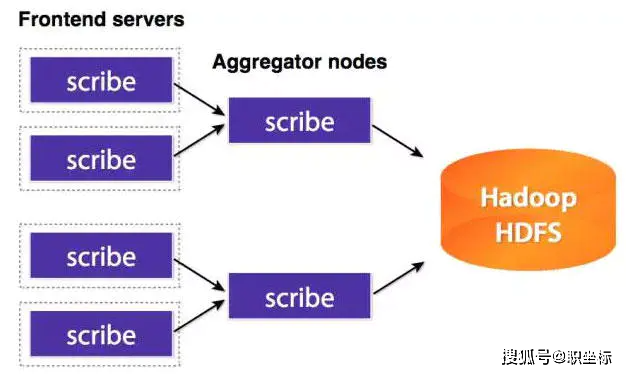
ScRibe
ScRibe是FACEbook开发的数据(日志)收集系统。已经多年不维护,同样的,就不多说了。
Splunk FoRwaRdeR
以上的所有系统都是开源的。在商业化的大数据平台产品中,Splunk提供完整的数据采金,数据存储,数据分析和处理,以及数据展现的能力。
Splunk是一个分布式的机器数据平台,主要有三个角色:
SeaRch Head负责数据的搜索和处理,提供搜索时的信息抽取。 indexeR负责数据的存储和索引 FoRwaRdeR,负责数据的收集,清洗,变形,并发送给indexeR
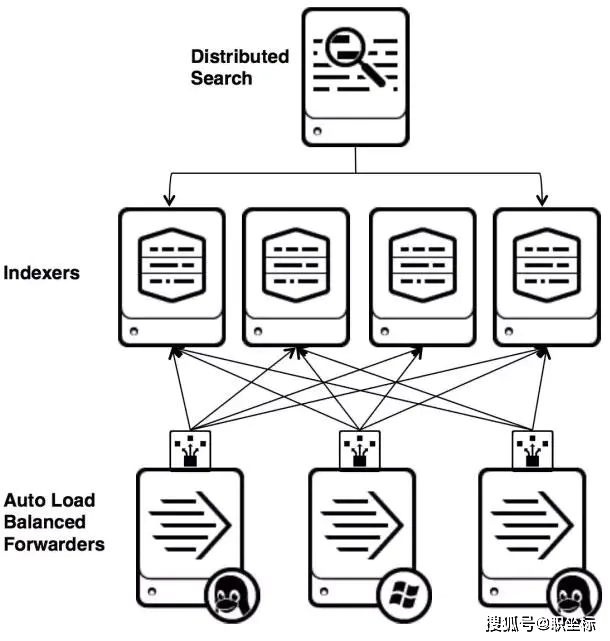
Splunk内置了对SYslog,TCP/UDP,Spooling的支持,同时,用户可以通过开发ScRIPt Input和ModulaR Input的方式来获取特定的数据。在Splunk提供的软件仓库里有很多成熟的数据采集应用,例如AWS,数据库(DBConnect)等等,可以方便的从云或者是数据库中获取数据进入Splunk的数据平台做分析。
这里要注意的是,SeaRch Head和indexeR都支持ClUSteR的配置,也就是高可用,高扩展的,但是Splunk现在还没有针对FARwaRdeR的ClUSteR的功能。也就是说如果有一台FARwaRdeR的机器出了故障,数据收集也会随之中断,并不能把正在运行的数据采集任务FAIlOVeR到其它的FARwaRdeR上。
总结
我们简单讨论了几种流行的数据收集平台,它们大都提供高可靠和高扩展的数据收集。大多平台都抽象出了输入,输出和中间的缓冲的架构。利用分布式的网络连接,大多数平台都能实现一定程度的扩展性和高可靠性。
其中FluMe,Fluentd是两个被使用较多的产品。如果你用ElasticSeaRch,Logstash也许是首选,因为ELK栈提供了很好的集成。Chukwa和ScRibe由于项目的不活跃,不推荐使用。
Splunk作为一个优秀的商业产品,它的数据采集还存在一定的限制,相信Splunk很快会开发出更好的数据收集的解决方案。