
工作人员齐整坐好,每个人都对着电脑全神贯注,一件又一件的“东西”在眼前划过,经过标准化处理就转到下一流程……这实际上是人工智能行业里的数据标注办公区一角。
由于深度学习的研究方向,人力密集型的数据标注工作是推进人工智能技术落地的重要环节之一。
很长一段时间以来,在过往AI的发展中数据的采集与标注行业没有过多地被关注,毕竟,与算法、算力这些高大上的东西相比,AI数据的生产总带着那么几分与AI技术的“科技感”截然不同的形象。
然而,随着AI的发展走向纵深,更多人发现这是一个误解,AI数据产业正在向着高专业化、高质量化的方向蓬勃发展。
根据2018年智研发布的《2019-2025年中国数据标注与审核行业市场专项分析研究及投资前景预测报告》,2018年该行业市场规模已达到52.55亿元,2020年市场规模有望突破百亿。有行业人士估计AI项目中会有10%的资金用于数据的采集和标记,2020年,数据标注行业最终市场规模将达到150亿。
而分享市场的,既有BAT、京东等互联网巨头,也有云测数据这种专注于高质量交付的专业化数据平台。
庞大的前景下,数据采集与标注也可以分NLP(自然语音处理)、CV(计算机视觉)等几个部分,随着数据需求量的增大、对数据质量要求的提高,其中的NLP越来越成为“硬骨头”,AI数据产业终将面临它带来的难题,也承袭这种难题下空出的市场空间。
AI的数据、算法和算力“轮流坐庄”,NLP到了“数据为王”的时代
芯片制程以及大规模并联计算技术的发展,使得算力快速提升后,AI能力的提升主要集中到了算法和数据上(算力提升当然还有价值,只是相对价值那么明显了,例如不可能对一个物联网终端设备有太多的算力设定要求)。
这方面,多年以来,人工智能技术都呈现“轮流坐庄”的螺旋提升关系:
算法突破后,可容纳的数据计算量往往变得很大,所以会迎来一波数据需求的高潮;而当AI数据通过某些方式达到一个新的程度时,原来的算法又“不够了”,需要提升。
2018年11月,Google AI团队推出划时代的BERT模型,在NLP业内引起巨大反响,认为是NLP领域里程碑式的进步,地位类似于更早期出现的Resnet相对于CV的价值。
以BERT为主的算法体系开始在AI领域大放异彩,从那时起,数据的重要性排在了NLP的首位。
加上两个方面的因素,这等于把NLP数据采集与标注推到了更有挑战的位置上。
一个因素,是NLP本身相对CV在AI数据方面的要求就更复杂。
CV是“感知型”AI,在数据方面有Ground Truth(近似理解为标准答案) ,例如在一个图片中,车、人、车道线等是什么就是什么,在采集和标注时很难出现“感知错误”(图片来源:云测数据)
而NLP是“认知”型AI,依赖人的理解不同产生不同的意义,表达出各种需要揣测的意图,Ground Truth是主观的。
例如,“这房间就是个烤箱”可能是说房间的布局不好,但更有可能说的是里边太热。人类语言更富魅力的“言有尽而意无穷”的特点,应用于AI时,需要被多方位、深度探索。
另一个因素,是AI数据的价值整体上由“饲料”到“奶粉”,对NLP而言这更有挑战。
大部分算法在拥有足够多常规标注数据的情况下,能够将识别准确率提升到95%,而商业化落地的需求现在显然不止于此,精细化、场景化、高质量的数据成为关键点,从95% 再提升到99% 甚至99.9%需要大量高质量的标注数据,它们成为制约模型和算法突破瓶颈的关键指标。
但是,正如云测数据总经理贾宇航所言,“图像采标有很强的规则性,按照规范化的指导文档工作即可,但NLP数据对应的是语言的丰富性,需要结合上下文等背景去理解和处理。”在高位提升这件事上,NLP数据更难。
例如,在订机票这个看似简单的AI对话场景中,想订票的人会有多种表达,“有去上海的航班么”,“要出差,帮我查下机票”,“查下航班,下周二出发去上海”……自然语言有无穷多的组合表现出这个意图,AI要“认得”它们,就需要大量高质量的数据的训练。
由此,我们再来理解商业机会。
数据采集与标注的公司有很多,从巨头的“副业”到AI数据专业化平台,总体而言主要玩家如图所示:
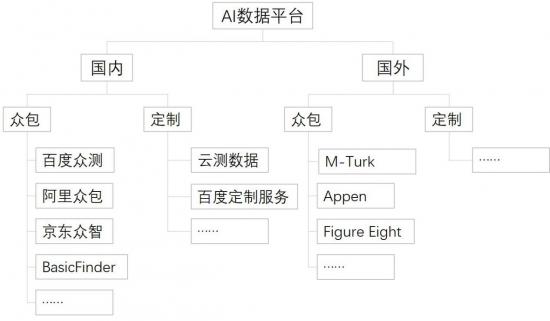
除此之外,更多中小玩家甚至几十人的草台班子数不胜数。在中国,目前全国从事数据标注业务的公司约有几百家,全职的数据标注从业者有约20万人,兼职数据标注从业者有约100万人。
易入门、难精通,而上述两大因素决定NLP数据面临巨大的挑战,做得好的就更少。
在数据“坐庄”NLP的大背景下,空出了大量的商业机会,而客观上的高要求阻却了大量低门槛入场的玩家,NLP数据相对于CV更像一个蓝海。
打破单纯“体力活”标签,NLP数据采集与标注从四个方面自我演进
有机会就总有人会进场,不久前,中国人工智能高峰论发布了中国人工智能科技服务商50强,既有商汤、旷视这种明星企业,也出现了榜单内唯一的AI数据服务商云测数据,这显示AI数据正在进入“主流圈”,在蓝海中尝试跑出独角兽企业。
当然,前提是平台能够解决好NLP数据的痛点问题。
事实上,CV的“感知”需求使得“体力活”可能就能够胜任大多数据生产工作(谁不认识一辆车、一个人呢),而“认知”的NLP数据要突围,只是“体力活”早已经不够。
至少目前来看,行业玩家在四个方面有所动作,或正在解决NLP数据痛点问题。
1、业务模式,用“定制化”迎合商业落地期的NLP
曾有媒体向Google工程师提起M-Turk的时候,他表示“我们不敢用Turk标注”,因为回收的数据良莠不齐。
众包模式(在公开平台发布任务,自由申领)是曾经的AI数据产业主流,拥有数据丰富性和多样性的优势,不过数据质量比较难以把控。在数据精细化要求的今天,很多需求方都转向了“定制化”(一对一,以项目制的方式完成交办的数据任务)服务模式。
例如,云测数据的“定制化”服务模式,跟的就是需求方复杂、精深而个性化的数据要求。具体到NLP,在数据采集上满足特定人物(老人、妇女、小孩)、特定场景(家居、办公、商业等)、不同方言的声音/文本数据采集;在数据标注上进行需求的对接、理解清楚场景化要求再分发尽量具体的规范指导(同样一句话在不同交流目的中可能需要标注不同的内容,例如“我没钱”在信贷服务中意味着潜在客户,在理财服务中则表达拒绝的态度)。
当然,众包模式也有它的优点,能够轻量化承载大量相对简单的数据需求,而场景化的定制模式则更专业,主要依靠自有员工和基地 ,像云测数据就在华东、华南、华北拥有自建标注基地,这种玩法显然更适合匹配客单价更高的场景化、定制化需求,NLP是典型。
2、管理流程,从“粗放制造”到“精益制造”
既然数据采集与标注很像是工厂的流水线,那么如果要提升数据的精准度,其实就如同“制造业”升级那样需要进行“粗放制造”到“精益制造”的转变,首要体现在管理流程的优化上。
无论是从平台接取任务的众包团队,还是直接对接需求方的定制化服务平台,至少,草台班子式的做法已经不适合NLP对数据的要求。
高精准度、高效率,都依赖管理流程的优化,以云测数据为例,具体做法包括这几个大方向:
标注、审核、抽检的层层把关:标注人员的结果交由另一批人进行审核,打回不合格的,最终再由质检进行抽检,大体如此,可能步骤更复杂;
人才类型的基础分类:文本、语音、图像标注人员不相互混用;
擅长场景的优先任务派发:在同等条件下,擅长对应场景的人优先派发给任务。
例会制度:如同精细化管理的制造业一样,早会、晚会、周会、月会,总结问题、提醒改进。
……
而无论如何,管理流程的事,说得再多,日常工作的落实才是最重要的。
3、职业技能,专业培训摆脱“低水平重复”
“不要门槛”意味着更低的价值,在人员个人能力上,NLP在逐渐抛弃那些“无门槛”入局的人,尤其是在特定的场景需求下。
例如,这是一个非常简单的NLP数据标注实例:

它的需求可能只有初中语文即可。但是,NLP的数据需求早已超过这样的标注太多。
例如,客服询问用户是否购买此商品时,&ldquo