
下面这个模型在一项图像识别竞赛中经过了数天训练。这是个相对比较简单的模型,其AUC最初是0.9,符合比赛将AUC控制在0到1之间的要求,除此之外我对比赛也没有太高的期望。也正因如此,当我照例评估重量模型,对模型进行训练时,看到如下结果大吃一惊:
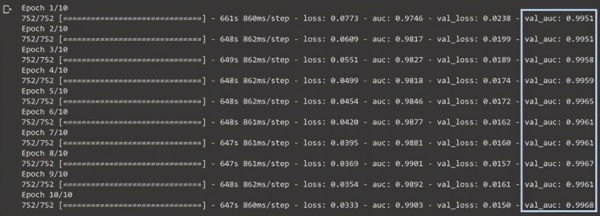
在当时比赛的实时排行榜中,排名首位的AUC值为0.965,而我当时的有效AUC值达到了0.9968,离获胜拿奖仅有一步之遥,在一百多个队伍中遥遥领先,让我难以置信。深度学习之神好像是在这天点化了我,让我在权重初始化上取得了这样傲人的成绩,简直像有了优化超能力一样厉害。
这个结果好的让人难以置信。虽然我很想相信模型给出的数据,但我仍持有一丝怀疑。我一次又一次地对模型预测进行评估,起初测试了部分数据,然后测试了全部数据。结果是肯定的:验证分数接近完美。
因此我确信自己找到了获胜的捷径,准备拿下第一名,带着激动的心情,我赶忙将模型对测试数据的预测提交了。奖金唾手可得。
而比赛分数令人震惊。

0.5分。即便是随便提交一个预测,或者是什么都不做仅仅是把比赛提供的样本文件提交都能拿到0.5分。我当时获得的魔法般的顿悟也就比瞎猜强了一点。
结果出来之后,我花了30多个小时,复盘数据,试图找出哪里出了问题,整个人精疲力竭。预测中肯定那儿除了问题,可能是文件传错了。
然而,这30个小时也不过是白费功夫。我花了九牛二虎之力更正结果,但预测结果值仍然很低。
到底是哪里出问题了?
答案是:数据泄露。数据泄露是个很简单的概念,但我就直直地走进了它的陷阱。在模型训练中,我的编程没有任何问题,模型也正确依照测试数据进行了训练,问题出现在了不易发现的地方。
简而言之,当模型遇到不该遇到的情况时,就会发生数据泄漏。在比赛中,我已经在多个会话中训练了模型,也就是说,我将从上一个会话中加载模型权重,训练模型并保存最佳性能的权重。由于计算时间限制,训练在多个会话中进行。
但是,在每个会话中,我都会重新运行整个代码,包括将数据随机分为训练和验证集的代码,因此每次培训的训练集并不相同。为避免这种情况,可以设置一个种子来划分训练/验证组,而这是我(非常)没有提前采取的措施。
尽管每次的训练数据都不同,但模型的权重(它所了解的信息)却被传递了下来。因此,经过足够的培训后,该模型已被暴露给整个数据集。
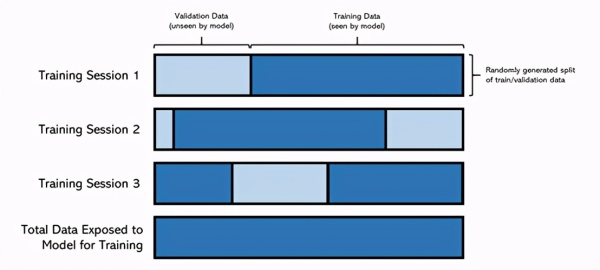
由于机器学习模型本身具有惰性,所以该模型会放弃学习,转而对数据进行记忆,这对没有感情的网络来说非常简单,也就导致这种现象发生过很多次。因此,面对从未见过的数据时,这个模型就无能为力了。
由于该模型已经在之前的训练中见过验证数据,所以才能得到近乎完美的0.9968,让我误以为这就是模型本身的能力。如果回忆一下模型早期的性能,想一想为什么验证分数会高于训练分数,就会明白这其实是一个相当奇怪且罕见的现象。
所以,大家在接下来的每一个实践中都要牢记这重要的一课:如果结果太过完美,让人不敢相信,那十有八九这个结果有问题。
这是一种数据泄露,其他类型的泄露包括:
预处理。如果在拆分之前处理数据,那可能会导致信息泄漏。例如,如果你在整个数据集中使用均值之类的方法,则训练集将包含有关验证集的数据,反之亦然。 时间。如果在预测问题涉及到了时间,那简单的随机训练/验证拆分无效。也就是说,如果要基于A和B预测C,则应在[A,B]上训练模型,而不要像[C,A]那样训练。这是因为知道了之后的数据点C的值,模型就可以预测之前的数据点B。
在事情太过完美的时候三思是个好习惯,但也要注意其中微妙的细节。比如说,分数增加的幅度很大,但不一定是很奇怪的现象;而当模型对测试数据进行预测时,其性能又很差劲。
实际上,最好的办法是注意以任何方式分割数据的目的,以便将它们分为训练/验证/测试集,并尽早进行。此外,设置种子是强有力的保障。
从更开放的角度上讲,数据泄漏可能是有益的。如果模型看到了不应该看到的数据,但是看到的数据有助于提升其概括能力,帮助学习,那么数据泄漏是有好处的。
例如,Kaggle的排名系统。该系统由一个公共排行榜和一个私人排行榜组成。在比赛结束之前,用户可以访问所有训练内容和部分测试内容(在该系统中可访问25%的内容,用于确定公共排行榜上的位置)。但是,比赛结束后,测试内容的另75%将用于评估模型,以确定最终私人排行榜的排位。
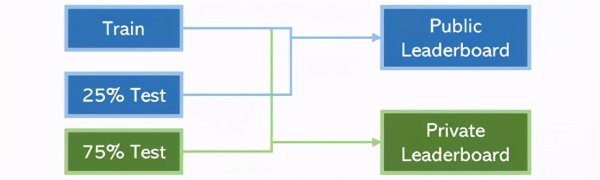
不过,如果我们能利用这25%的测试内容来提高私人排行榜上分数,这就算是数据泄露。
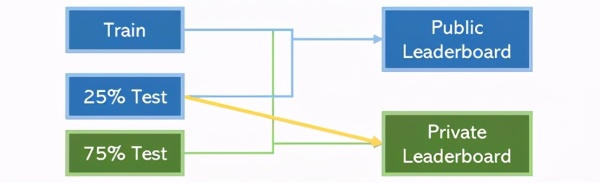
在Kaggle竞赛中,相对常见的做法是在了解其他25%测试数据的情况下对75%测试数据进行某种预处理。比如,可以采用PCA来降低尺寸。这通常都会提升模型性能,因为数据一般都是越多越好。
我们在寻找提高数据连接性方法的道路上应永不停歇;一般来说,永远不要将任何复杂的事件标记为纯粹的坏(或好)事件。
总而言之,数据科学家应致力于为模型提供更多的数据,但要把不同用处的数据区分开。此外,为了不让希望破灭,你应该消极地编程。毕竟,只有预期了最差的结果,面对问题才能淡定处理,面对成功也能欣喜若狂。