
本文经AI新媒体量子位授权转载,转载请联系出处。
FACEbook AI,更准确地说是Meta AI,刚刚发布了自监督语音处理模型XLS-R,共支持128种语言。
 这项技术与Meta公司最新“元宇宙”愿景紧密相关。
相互交谈是人们互动的一种自然方式,随着语音技术的发展,未来的虚拟世界可以使用我们技术进行互动,虚拟体验将与物理世界融为一体。
说人话,就是让母语不同的人在元宇宙里社交:一位说着英语,一位说着汉语,两人可以靠XLS-R在元宇宙中无障碍对话。
这项技术与Meta公司最新“元宇宙”愿景紧密相关。
相互交谈是人们互动的一种自然方式,随着语音技术的发展,未来的虚拟世界可以使用我们技术进行互动,虚拟体验将与物理世界融为一体。
说人话,就是让母语不同的人在元宇宙里社交:一位说着英语,一位说着汉语,两人可以靠XLS-R在元宇宙中无障碍对话。
 实际效果如何呢?
MetaAI在HuggingFACE上发布了试用版语音直译模型,支持从22种语言转换到16种语言,我们先来试试它的英译中效果。
实际效果如何呢?
MetaAI在HuggingFACE上发布了试用版语音直译模型,支持从22种语言转换到16种语言,我们先来试试它的英译中效果。
 (虽然翻译腔较浓,但仍算准确,7秒钟的句子完成翻译仅1.53秒)
我们知道,世界上的语言有上千种,要用AI实现这些语言的互通并非易事。
一般语料库的丰富程度决定了语言翻译模型的质量,语音翻译一般集中于几个资源多大语种之间。但是由于小语种往往语料匮乏,使用这类母语的人往往很难获得较高的AI翻译质量。
XLS-R通过自监督技术对10倍的语音数据进行训练,大大改善了以前的多语言模型,尤其是小语种的处理。
XLS-R的原理
XLS-R基于FACEbook去年发布的wav2vec 2.0技术。
wav2vec 2.0与BERT类似,是通过预测音频Mask部分的语音单元来训练的。它们的区别是,语音音频是一种连续的信号,不能轻易清晰地分割成单词或其他单位。
wav2vec 2.0通过学习25毫秒长的基本单元来解决这个问题,以便能够学习高级上下文表示。
(虽然翻译腔较浓,但仍算准确,7秒钟的句子完成翻译仅1.53秒)
我们知道,世界上的语言有上千种,要用AI实现这些语言的互通并非易事。
一般语料库的丰富程度决定了语言翻译模型的质量,语音翻译一般集中于几个资源多大语种之间。但是由于小语种往往语料匮乏,使用这类母语的人往往很难获得较高的AI翻译质量。
XLS-R通过自监督技术对10倍的语音数据进行训练,大大改善了以前的多语言模型,尤其是小语种的处理。
XLS-R的原理
XLS-R基于FACEbook去年发布的wav2vec 2.0技术。
wav2vec 2.0与BERT类似,是通过预测音频Mask部分的语音单元来训练的。它们的区别是,语音音频是一种连续的信号,不能轻易清晰地分割成单词或其他单位。
wav2vec 2.0通过学习25毫秒长的基本单元来解决这个问题,以便能够学习高级上下文表示。
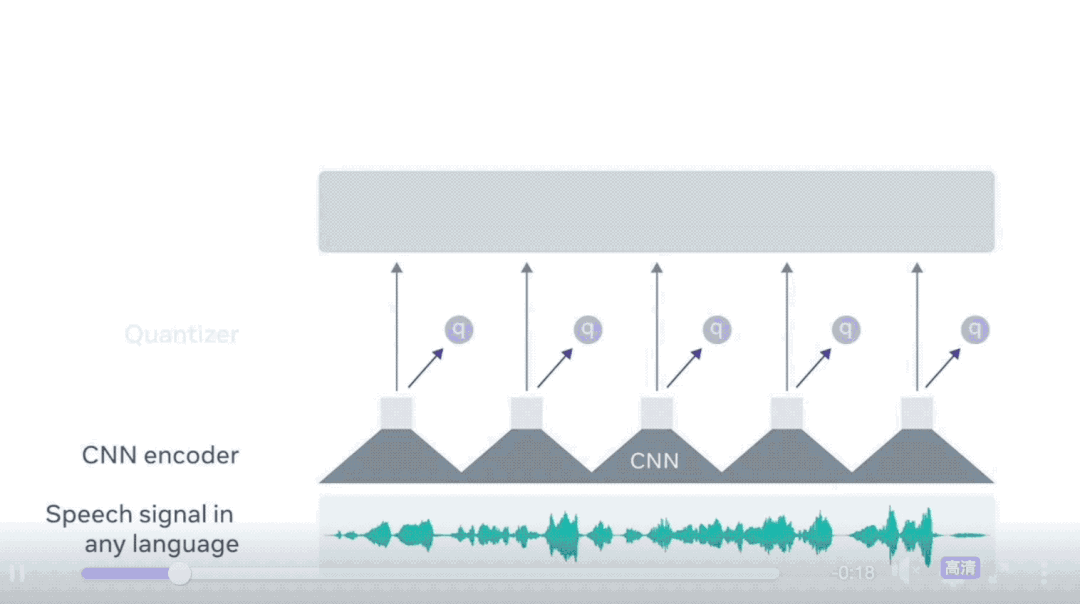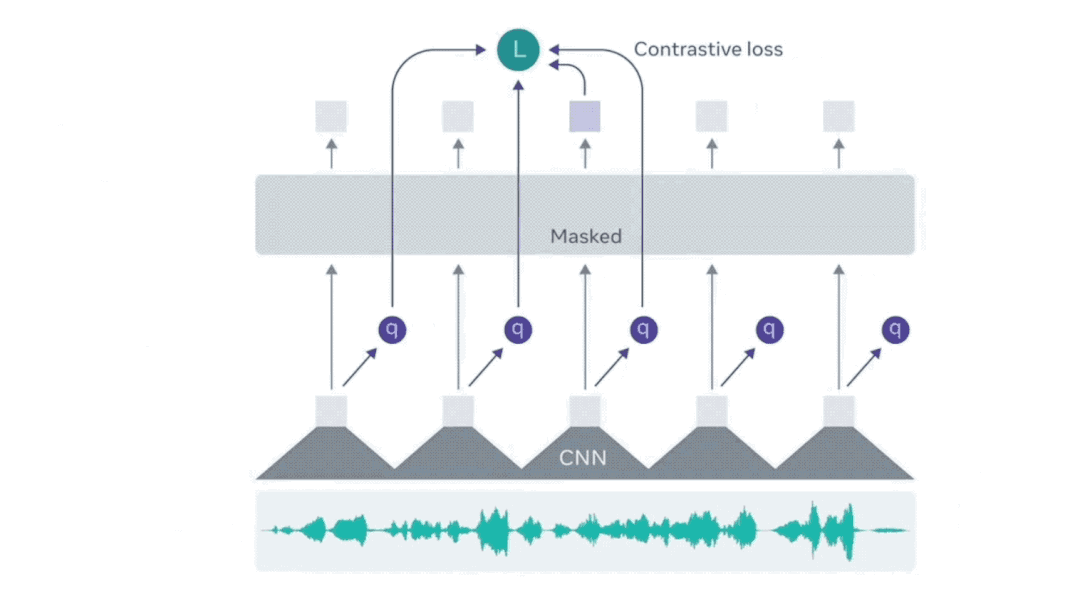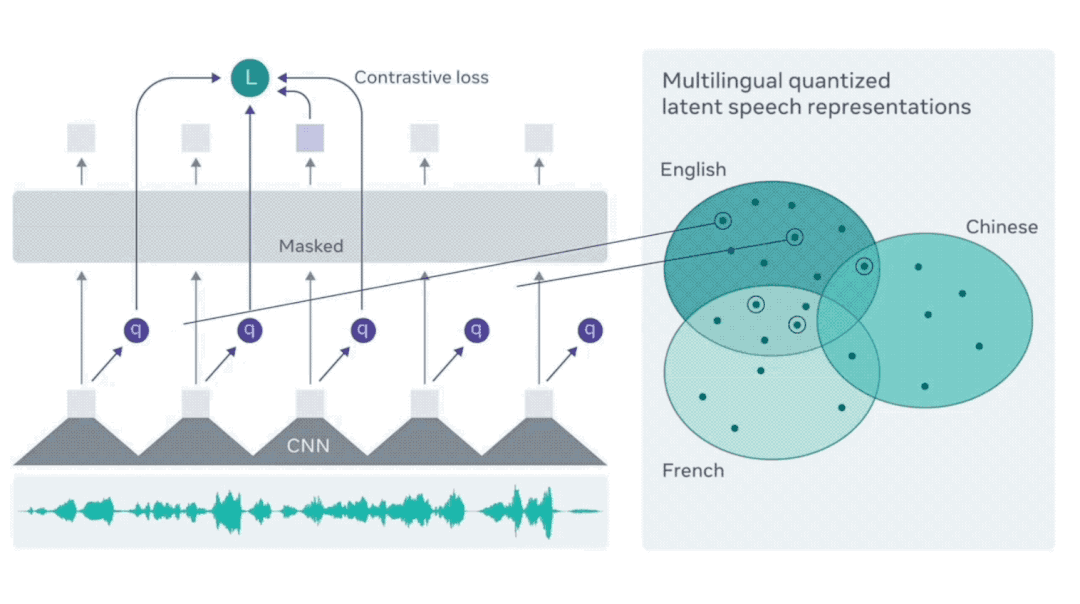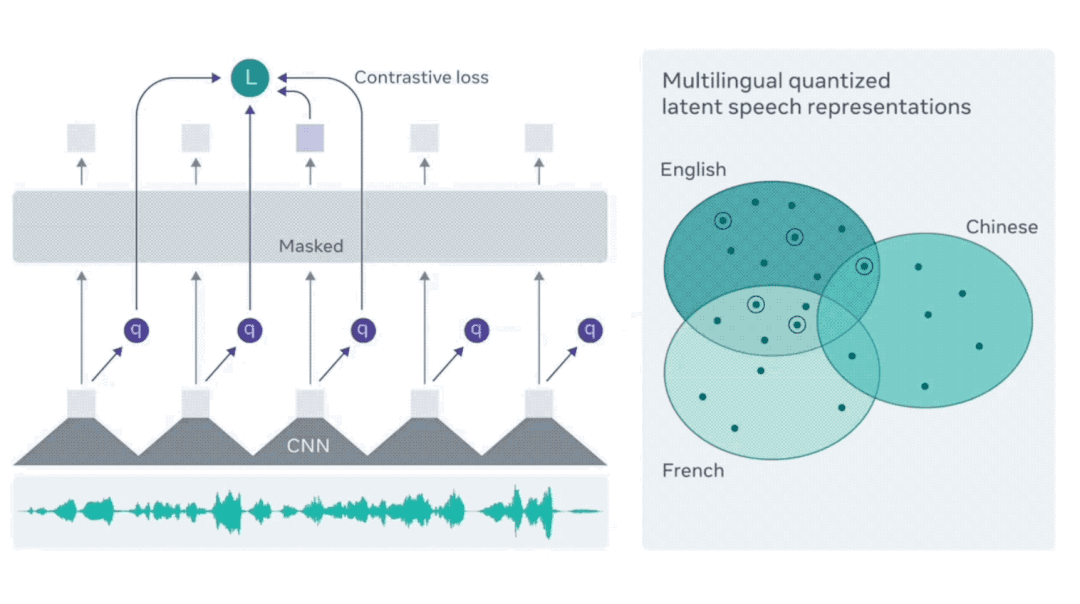 在仅拥有一小时的标记训练数据的情况下,wav2vec 2.0能通过后续无监督的训练数据,在LibReSpeech测试基准的100小时子集上达到SOTA水平。
之后,FACEbook又推出了完全无监督的高性能语音识别模型wav2vec-U,它纯粹从录制的语音音频和未配对的文本中学习。
为了wav2vec-U让学习识别音频录音中的单词,FACEbook训练了一个GAN。生成器根据嵌入在自监督表示中的每个音频段,预测与语言中的声音对应的音素。
而鉴别器负责评估预测的音素序列是否真实。最初,转录非常糟糕,但随着时间的推移,随着鉴别器的反馈,转录变得准确。
在仅拥有一小时的标记训练数据的情况下,wav2vec 2.0能通过后续无监督的训练数据,在LibReSpeech测试基准的100小时子集上达到SOTA水平。
之后,FACEbook又推出了完全无监督的高性能语音识别模型wav2vec-U,它纯粹从录制的语音音频和未配对的文本中学习。
为了wav2vec-U让学习识别音频录音中的单词,FACEbook训练了一个GAN。生成器根据嵌入在自监督表示中的每个音频段,预测与语言中的声音对应的音素。
而鉴别器负责评估预测的音素序列是否真实。最初,转录非常糟糕,但随着时间的推移,随着鉴别器的反馈,转录变得准确。
 通过这种方式,它学会了区分生成器的语音识别输出和真实文本。
FACEbook在此基础上推出了包含53种语言的XLSR。
而最新发布的XLS-R有128种语言之多,语种数量是XLSR的两倍多,数据量更是后者10倍——共计长达43.6万小时的语音。
通过这种方式,它学会了区分生成器的语音识别输出和真实文本。
FACEbook在此基础上推出了包含53种语言的XLSR。
而最新发布的XLS-R有128种语言之多,语种数量是XLSR的两倍多,数据量更是后者10倍——共计长达43.6万小时的语音。
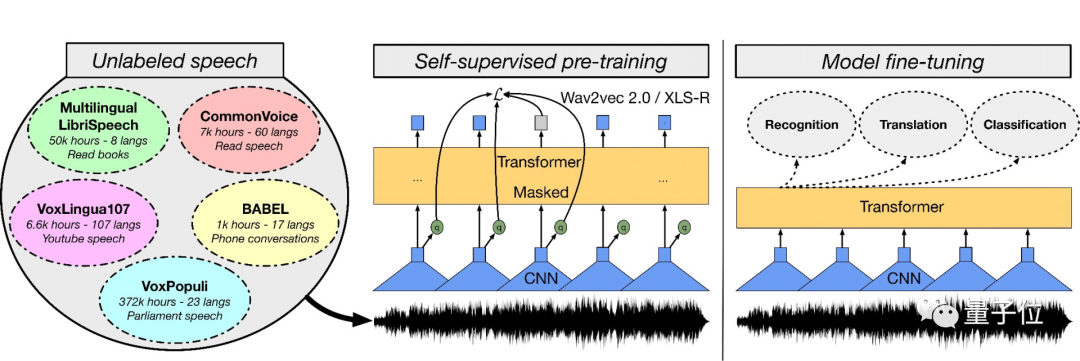 XLS-R共有20亿参数,它在测试的37种语言中,表现优于大多数语种先前的工作。甚至在老挝语等小语种识别上,也能低于之前的错误率。
XLS-R共有20亿参数,它在测试的37种语言中,表现优于大多数语种先前的工作。甚至在老挝语等小语种识别上,也能低于之前的错误率。
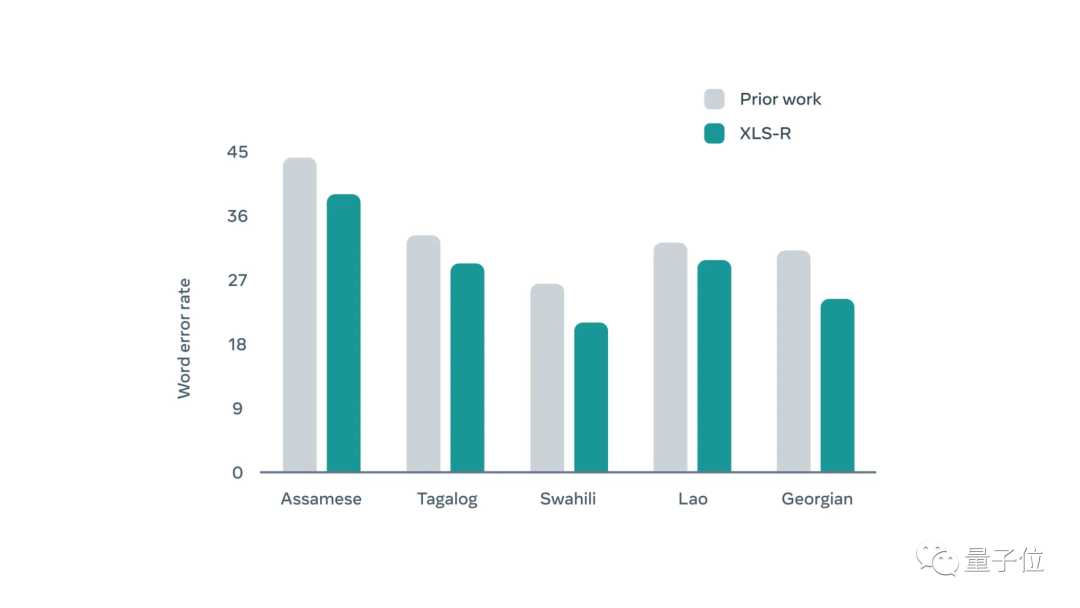 此外XLS-R也让低资源语言与英语之间的翻译大幅改进,例如从印度尼西亚语到英语的翻译,其中BLEU的准确性平均翻了一番。
COVoST-2语音翻译基准测试中,XLS-R在21个英语翻译方向上比之前技术平均提高了7.4 BLEU。
从下图中可以看出,XLS-R对低资源语种的提升尤为明显。
此外XLS-R也让低资源语言与英语之间的翻译大幅改进,例如从印度尼西亚语到英语的翻译,其中BLEU的准确性平均翻了一番。
COVoST-2语音翻译基准测试中,XLS-R在21个英语翻译方向上比之前技术平均提高了7.4 BLEU。
从下图中可以看出,XLS-R对低资源语种的提升尤为明显。
 此外官方还提供不同参数规模的语音识别模型,以及15种语言与英语之间的互译模型,供用户下载。
传送门
官方博客:
GITHub页:
论文地址:
试用网页地址:
微调方法简介:
此外官方还提供不同参数规模的语音识别模型,以及15种语言与英语之间的互译模型,供用户下载。
传送门
官方博客:
GITHub页:
论文地址:
试用网页地址:
微调方法简介:
Meta发布支持128种语言的全新语音模型:实现元宇宙跨语言交流
OpenMagic API
Need more than content? Move into the product flow.
If you are here for model access, pricing, developer docs, or the future API console, the dedicated product path now lives on api.openmagic.ai.