
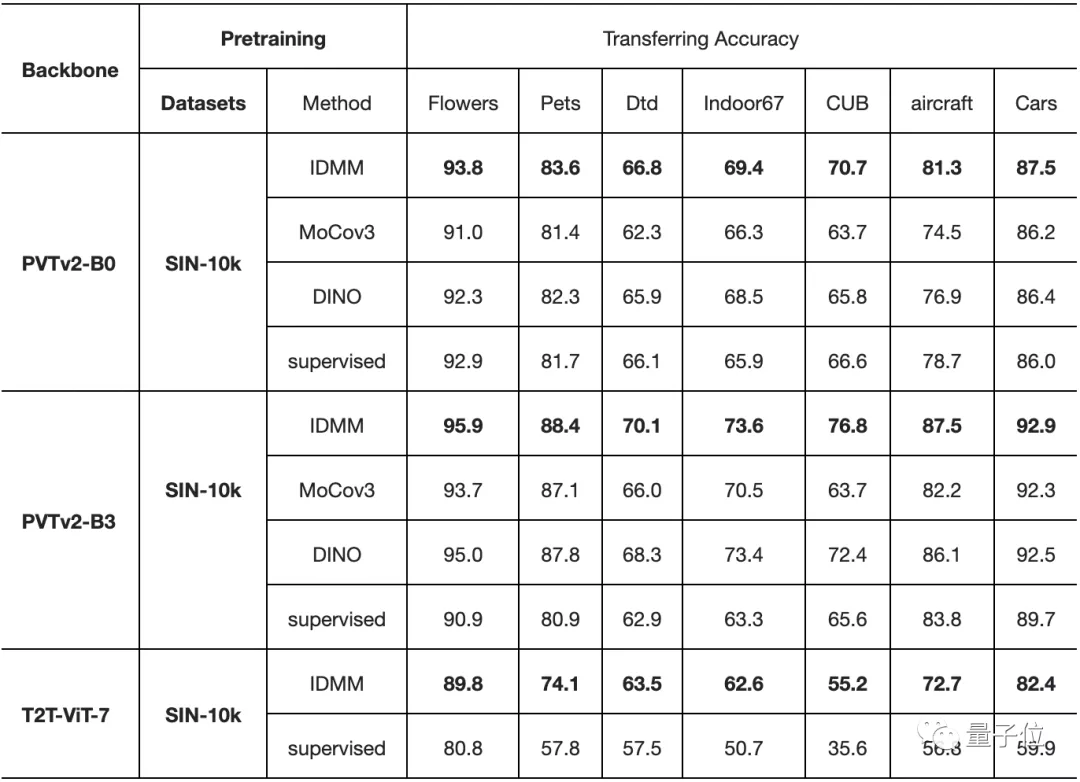
VIT在计算机视觉领域取得了巨大的成功,甚至大有取代CNN之势。但是相比CNN,训练VIT需要更多的数据,通常要在大型数据集JFT-300M或至少在imageNet上进行预训练,很少有人研究少量数据训练VIT。最近,南京大学吴建鑫团队提出了一种新方法,只需2040张图片即可训练VIT。他们在2040张花(floweRs)的图像上从头开始训练,达到了96.7%的准确率,表明用小数据训练VIT也是可行的。另外在VIT主干下的 7 个小型数据集上从头开始训练时,也获得了SOTA的结果。
而且更重要的是,他们证明了,即使在小型数据集上进行预训练,VIT也具有良好的迁移能力,甚至可以促进对大规模数据集的训练。
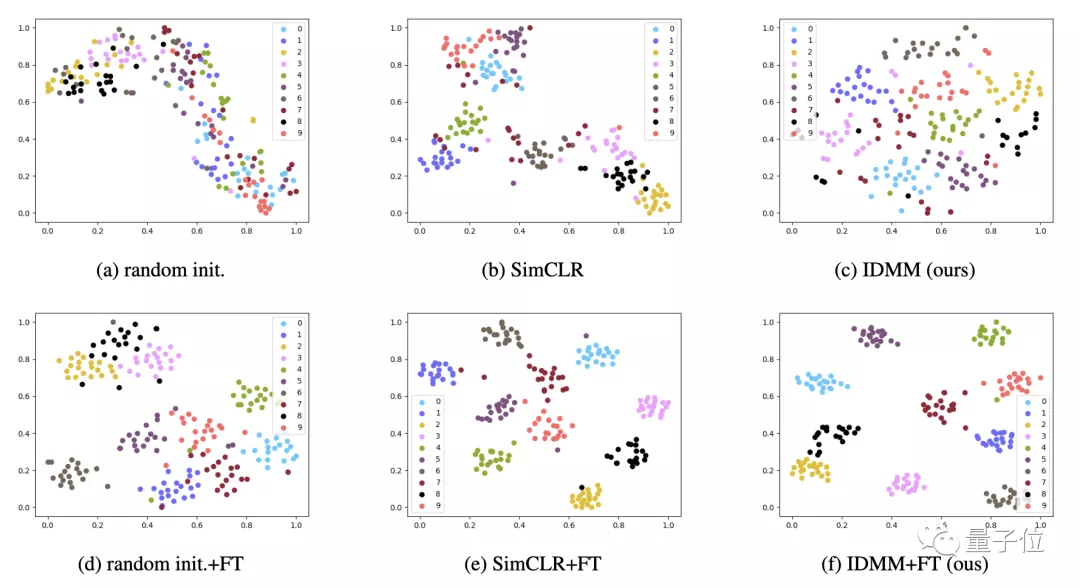
在这篇论文中,作者提出了用于自我监督 VIT训练的IDMM(Instance DiscRiMination wITh Multi-cRop and CutMix)。
我们先来看一下VIT图像分类网络的基本架构:
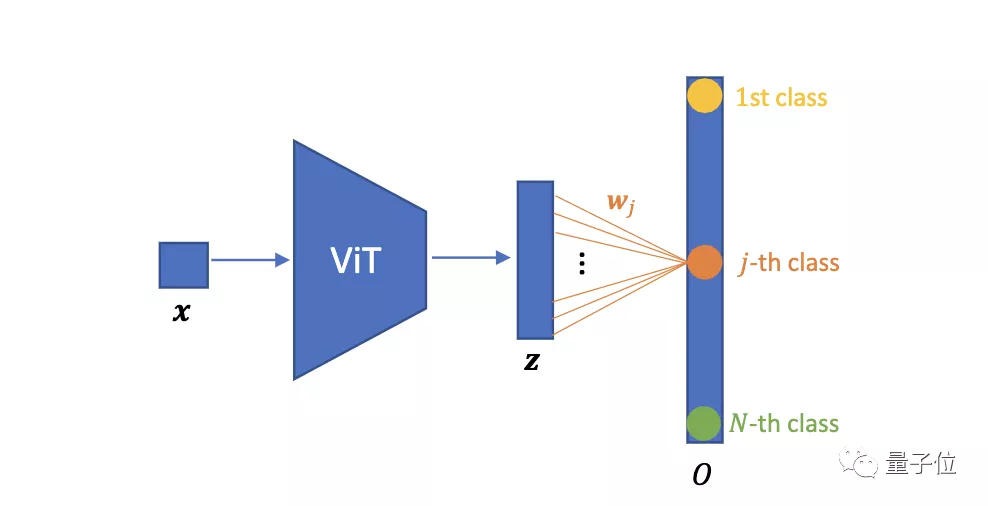
然后,使用全连接层W进行分类,当类的数量等于训练图像的总数N时,即参数化实例判别。
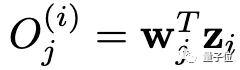
我们把O送入SoftMax层,就得到一个概率分布P⁽ⁱ⁾。对于实例判别,损失函数为:
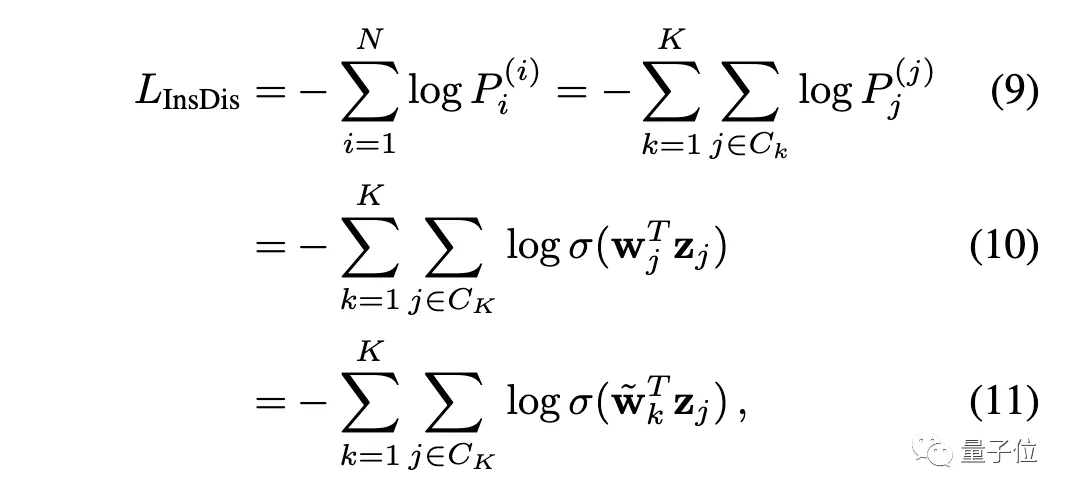
对于深度聚类,其损失函数为:
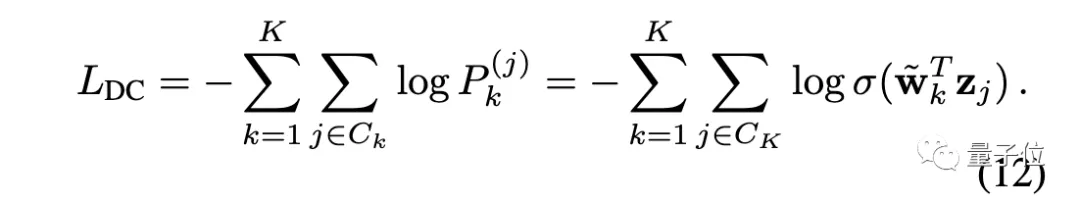
可以看出,只要适当设置权重(让wⱼ = ~wₖ ),就可以让实例判别等价于深度聚类。
作者之所以选择参数化的实例判别,还有一个重要的原因:简单性和稳定性。不稳定性是影响自监督VIT训练的一个主要问题。实例判别(交叉熵)的形式更稳定,更容易优化。

吴建鑫本科和硕士毕业于南京大学计算机专业,博士毕业于佐治亚理工。2013年,他加入南京大学科学与技术系,任教授、博士生导师,曾担任ICCV 2015领域主席、CVPR 2017领域主席,现为PatteRn RecognITion期刊编委。