
在制造业中,CAD 的应用十分广泛。凭借着精准、灵活、快速的特性,CAD 已经取代了纸笔画图,并且不再只是应用于汽车制造、航空航天等领域,哪怕小到一个咖啡杯,生活中几乎每个物件都由 CAD 画图建模。
CAD 模型中最难制作的部件之一就是高度结构化的 2D 草图,即每一个 3D 构造的核心。尽管时代不同了,但 CAD 工程师仍然需要多年的培训和经验,并且像纸笔画图设计的前辈们一样关注所有的设计细节。下一步,CAD 技术将融合机器学习技术来自动化可预测的设计任务,使工程师可以专注于更大层面的任务,以更少的精力来打造更好的设计。
在最近的一项研究中,DeepMind 提出了一种机器学习模型,能够自动生成此类草图,且结合了通用语言建模技术以及现成的数据序列化协议,具有足够的灵活性来适应各领域的复杂性,并且对于无条件合成和图像到草图的转换都表现良好。
具体而言,研究者开展了以下工作:
使用 PB(Protocol BuFFeR)设计了一种描述结构化对象的方法,并展示了其在自然 CAD 草图领域的灵活性;
从最近的语言建模消除冗余数据中吸取灵感,提出了几种捕捉序列化 PB 对象分布的技术;
使用超过 470 万精心预处理的参数化 CAD 草图作为数据集,并使用此数据集来验证提出的生成模型。事实上,无论是在训练数据量还是模型能力方面,实际的实验规模都比这更多。
CAD 草图展示效果图如下:
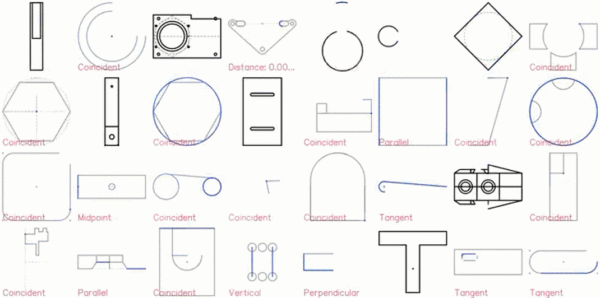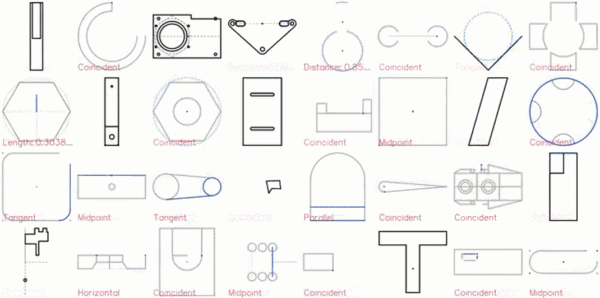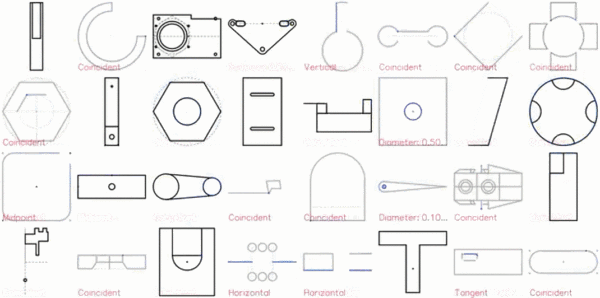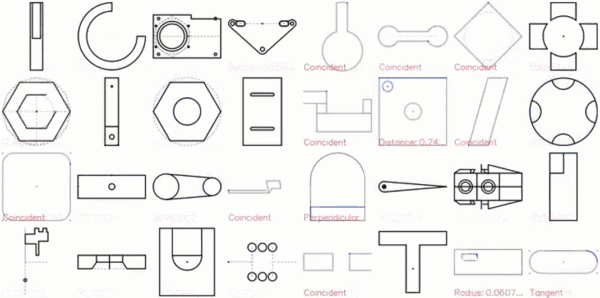
特写镜头展示:

对于 DeepMind 的这项研究,网友的评价非常高。用户 @TheodoRe Galanos 表示:「非常棒的解决方案。我曾使用 SketchGRaphs 作为多模态模型的候选方案,但序列的格式和长度太不容易处理了。等不及在建筑设计中也使用这种方法了。」
 草图之于 CAD
草图之于 CAD
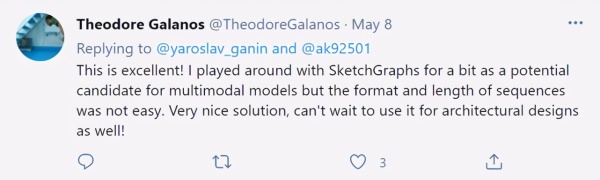
2D 草图是机械 CAD 的核心,是构成三维形式的骨架。草图由通过特定的约束(例如正切、垂直和对称)相关联的各种线、弧、样条线和圆组成。这些约束旨在传达设计意图,并定义在实体的各种变换下,形状应该如何发生变化。下图说明了约束是如何将不同的线、弧等几何图形组合创建成特定的形状的。虚线显示了丢失约束时的另一个有效的解决方案。所有的几何实体都位于一个草图平面上,共同形成封闭的区域,供后续操作(例如放样和拉伸)使用,以生成复杂的 3D 几何。
 约束:草图逃不开的问题
约束:草图逃不开的问题
约束( constRAInt )使草图比看起来要复杂得多。它们展现了可以间接影响草图中每个实体的关系。例如,在上图中,如果在底角保持固定的状态下向上拖动两个圆弧相交的点,则心形的大小会增大。这种转变看似简单,但实际上是所有约束共同作用的结果。
这些约束确保了当每个实体的尺寸和位置发生变化时,形状仍保持着设计者想传达的状态。由于实体之间复杂的相互作用,很容易意外地指定一组约束,从而导致草图无效。例如,同时满足平行和垂直约束的两条线是无法绘制的。在复杂的草图中,约束依赖关系链会导致设计人员确定要添加的约束变得极为困难。此外,对于给定的一组实体,有许多等效的约束系统能产生类似的草图。
一个高质量的草图通常会使用一组保留设计意图的约束,这意味着即使更改了实体参数(例如尺寸),草图的语义也得以保留。简而言之,无论实体尺寸如何变化,上图中的心形永远是心形。捕捉设计意图与选择一致的约束系统的复杂性使草图生成变成极其困难的问题。
草图与自然语言建模的相似性
草图构造的复杂性有些类似于自然语言建模。在草图中选择下一个约束或实体就像生成句子中的下一个单词,而两者中的的选择又必须在语法上起作用(在草图中形成一个一致约束系统),并保留设计意图。
在生成自然语言方面,已经有了许多成功的工具,其中表现最佳的无疑是在大量现实世界数据上进行训练的机器学习模型。比如 2017 年的 TRansfoRMeR 架构,展示了强大的连贯造句的能力。这些自然语言模型中的规律,是否可以用来绘制草图呢?
数据
Onshape 是维度驱动设计的一个参数化实体建模软件。但为了存储和处理草图,研究者使用 PB,而不是 Onshape API 提供的原始 JSON 格式。使用 PB 具有双重的优势:由于移除了不必要的信息,结果数据占用的空间更少;使用 PB 语言可以轻松地为结构各异的复杂物体定义精准的规格。
一旦设定好所有必要的对象类型,就需要将数据转换为可以通过机器学习模型来处理的表格。研究者选择将草图表示为 Tokens 序列,以便使用语言建模生成草图。文本格式包含了结构和数据的内容,这样使用的优势是可以应用任何现成的文本数据建模方法。不过,即使对于现代语言建模技术,这样做也是有代价的:模型为了生成有效的语法,将额外占用模型容量的一部分。
解决的手段就是避免使用字节格式 PB 定义的通用解析器,利用草图格式的结构来自定义构建设计解释器,即输入一系列代表草图创建过程中各个决策步骤有效选择的 Tokens。在这种 Tokens 序列的格式下设计解释器会导致 PB 消息有效。
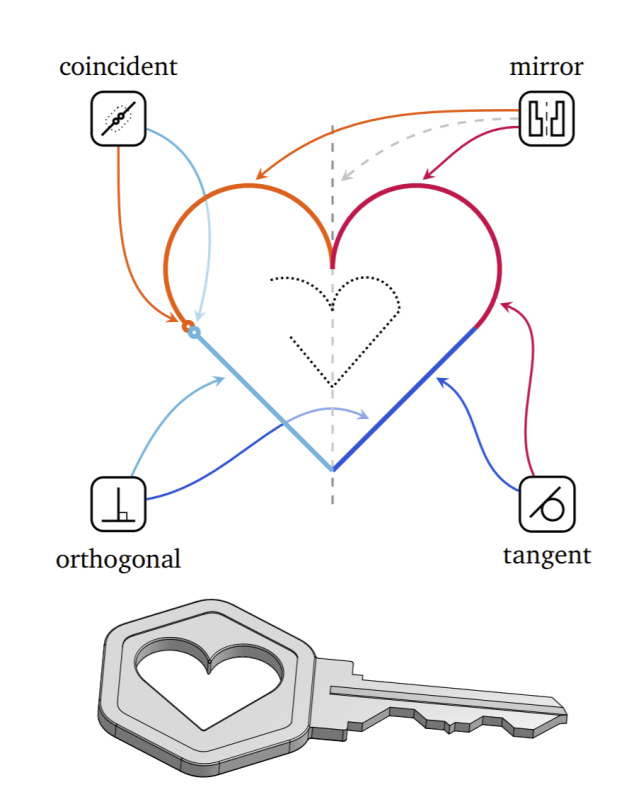
在这种格式下,研究者将消息表示为 tRIPlets 序列(,,),其中是 Token 的索引。给定一系列这样的 tRIPlets,推断每个 Token 对应的确切字段是可能的。实际上,第一个 Token(,,)始终与 objects.kind 相关联,因为它是创建一个草图消息的首选。第二个字段取决于1 的具体值。如果1= 0,那么第一个对象是一个实体,这意味着第二个 Token 对应于 entITy.kind。该序列的其余部分以类似的方式关联。字段标识符及其在对象中的位置构成了 Token 的上下文。因为它使解释 tRIPlets 值的含义以及了解整体数据结构更容易,研究者将此信息用作机器学习模型的其他输入。

如上图所示,草图包含了一条线实体和一个点实体。在左列的每个 tRIPlet 中,实际使用的值以粗体显示。右列显示了 tRIPlet 与对象的哪个字段有关联。
从模型中取样
建立模型的主要目标是估计数据集 D 中的 2D 草图 data 的分布。就像上文提到的,研究者将像 Token 序列一样处理草图。在这项工作中,由于相关原始文本格式的序列长度挑战,只会考虑使用用字节和 tRIPlet 来表示。
从字节模型取样很简单,该过程与任何典型的基于 TRansfoRMeR 的语言建模过程相同,而 TRIPlet 模型需要更多的定制处理。
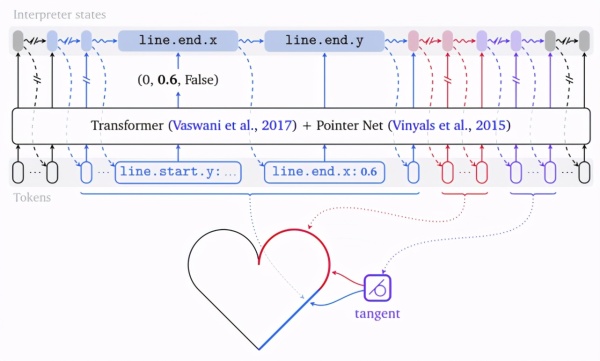
上图展示了 TRIPlet 的处理过程:首先将特殊的 BOS Token 嵌入并提供给 TRansfoRMeR。然后,TRansfoRMeR 输出一组 tRIPlets,每个可能的 Token 组一个。为了确定具体需要发出哪个 Token,应用从数据规格中自动生成的解释器(状态机),再选择合适的 Token 组并关联在合成对象中具有字段的 tRIPlet 的活动组件。填入适当的字段后,解释器转换到下一个状态并生成一个输出 Token,然后将其反馈到该模型。当状态机收到最外层重复字段(即 object.kind)的 “end&Rdquo; tRIPlet 时,停止该过程。
实验
研究者使用了从 Onshape 平台上公开可用的文档库中获得的数据对方法进行验证。遵循自回归生成模型的标准评估方法,研究者使用对数可能性作为主要的定量指标。此外,研究者还提供了各种随机和选定的模型样本以进行定性分析评估。
训练细节
研究者使用 128 个通道的批次训练模型以进行 10^6 个权重更新。每个通道都可以在 tRIPlet 设置中容纳 1024 个 Tokens 的序列,在字节设置中容纳 1990 个 Tokens。为了提高占用率并减少计算浪费,研究者动态地填满了通道,在继续前进到下一条道之前将尽可能多的例子打包。每个批次由 32 个 TPU 内核并行处理。
此外,研究者还使用了 AdaM 优化器,学习率为 10^&MinUS;4,梯度范数为 1.0,所有实验均采用 0.1 的失活率。
实验结果 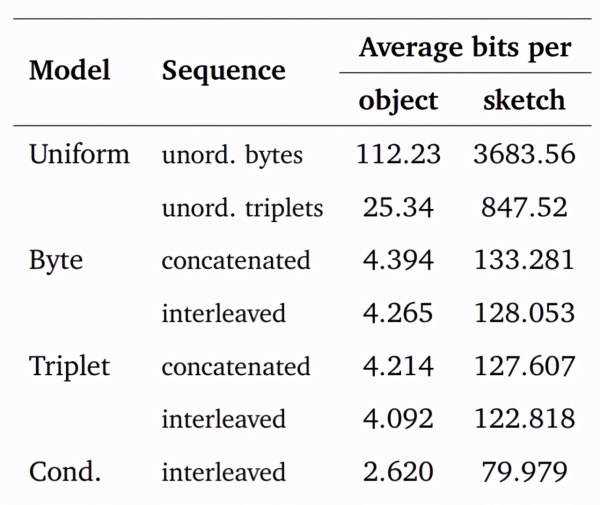
如上图所示,各种模型的可能性都被测试到了。第三列是草图测试样本中每个对象的平均字节数,第四列是第三列乘以对象数。
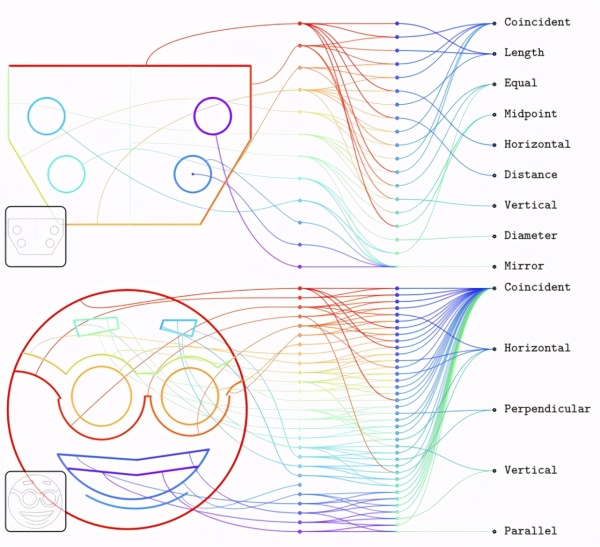
下图是从 tRIPlet 模型中取样的实体与约束。第一列节点代表了不同的实体,节点从上至下遵循生成的顺序。第二列代表着不同的约束,按照序列索引排序。第三列是从频率最高到最低的约束类型。

下图是条件模型的实体和约束。左下角是输入位图,下例说明了模型在分布外输入时的表现。
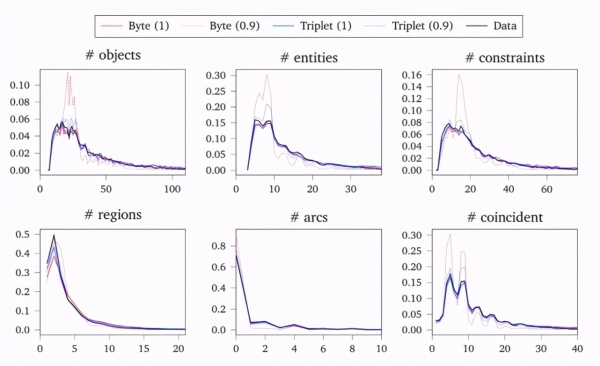
下图显示了从非条件模型取样的各种草图数据分布统计,而括号中的是 NUCleUS 取样的 top-p 参数。
这些只是最初的概念验证实验。DeepMind 表示,希望能够看到更多利用已开发接口的灵活性优势开发的应用程序,比如以各种草图属性为条件,给定实体来推断约束,以自动完成图纸。