
假设你给机器看了一段很长的游戏视频,在里面有砍树,打猎,造房子等,你的模型能否从这个非结构化的录像中自动地发现这些有意义的技能包?
在现实世界里,人类尤其具有这种将复杂任务有效分解为多个子任务的能力。这种能力帮助人类面对新环境时加速自身的学习过程并获得更好的泛化能力。
传统方法主要围绕概率图模型。这些工作将子任务结构建模为潜在变量,并从学到的后验中提取子任务标识。在一篇ICLR 2021的论文中,MIT-IBM Lab 淦创团队与蒙特利尔大学合作提出了:是否可以设计更智能的神经网络,使子任务结构自动在模仿学习中出现?具体而言,研究者设计了一个循环决策网络,使得子任务结构能够体现在每一步的表征中。
在该研究中,研究者提出有序记忆决策网络(OMPN)。模型可以经过正常的行为克隆(behavioR cloning)来发现子任务的层级,从非结构化示范中恢复子任务边界。在 CRaft 和 Dial 上进行的实验表明,在没有任何人类额外标注的情况下,子任务层次结构会自然地从模型中演化出。
 论文地址:https://openReview.net/pdf?id=vcopnwZ7bC 项目地址:https://Github.coM/ORdeRed-MeMoRy-RL/ MeMoRy 如何表达子任务?
论文地址:https://openReview.net/pdf?id=vcopnwZ7bC 项目地址:https://Github.coM/ORdeRed-MeMoRy-RL/ MeMoRy 如何表达子任务?
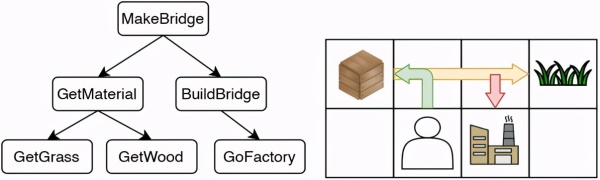
研究者提供了一个网格世界的示例用于说明。示例中有不同的原料(例如草)可供智能体拾取,还包括一家工厂以便智能体使用这些原料。假设智能体想要完成搭桥任务,该任务可以分解为树状多层结构。其中,根任务可以分为 “拾取原料&Rdquo; 和“制造桥梁&Rdquo;。“拾取原料&Rdquo;可以进一步分为 “拾取草&Rdquo; 和“拾取木头&Rdquo;。
为了能够实现上述的结构,智能体的记忆在每一步应该如何 “更新&Rdquo;?在下图中,将记忆划分为不同级别,对应不同层级的子任务。当‘t=1&Rsquo;时,模型仅从根任务“搭建桥梁&Rdquo; 开始,并 “展开&Rdquo; 得到 “拾取原料&Rdquo;,然后进一步“展开&Rdquo; 为“拾取木头&Rdquo;。这里的 “展开&Rdquo;(蓝色箭头)可以理解成一种“planning opeRaTor&Rdquo;,动作从最低层级的记忆中产生。在‘t<3&Rsquo;时,“拾取原料&Rdquo; 会被复制,但是当 “拾取木头&Rdquo; 完成后,即‘t=3&Rsquo;时,该子任务会被 “更新&Rdquo;。这里的“更新&Rdquo; 可以视为每个子任务的内部更新,而 “更新&Rdquo; 后的 “拾取原料&Rdquo; 通过 “展开&Rdquo; 重新得到下一个子任务 “拾取草&Rdquo;。同理“搭建桥梁&Rdquo; 一直被复制直到在‘t=5&Rsquo;(“拾取原料&Rdquo;完成)时进行 “更新&Rdquo;,然后“展开&Rdquo; 为“制造桥梁&Rdquo;和“前往工厂&Rdquo;。

这样的过程中,可以定义 “展开高度&Rdquo;,即每一时刻发生“展开&Rdquo; 的记忆的位置。研究者同时观察到,通过观察 “展开高度&Rdquo; 的变化,可以由此确定子任务的边界。例如从‘t=2&Rsquo;到‘t=3&Rsquo;,扩展位置从最低级别到中间级别,表明了低级别子任务的完成。从‘t=4&Rsquo;到‘t=5&Rsquo;,扩展位置从最低级别到最高级别,表明低级别和中级别子任务均已完成。所以目标就是希望通过合理的网络设计,让模型可以收敛到上述记忆更新规则。具体包括:
若模型认为当前底层子任务已被完成,则需要输出高展开位置,并从高层子任务中展开。 若模型认为当前底层子任务未被完成,则需要输出低展开位置, 并将高层任务复制,来实现 long-teRM dependency。
网络设计的数据流效果如下所示:
 从行为克隆中进行任务分解
从行为克隆中进行任务分解
主要的实验结果就是表明:正确的子任务结构的确可以通过行为克隆后,在模型中体现出来,而在这个过程中,没有任何额外的任务边界标注。在接下来示例中,将智能体的轨迹以及展开位置的变化进行可视化。经过学习后,模型学会在每个子任务快结束的时刻,将展开高度提高。在每个子任务的行进过程中,将展开高度保持低位,符合之前说的直觉。

在 CRaft 任务中,模型需要完成 4 个子任务来“造床&Rdquo;。

在 Dial 任务中,模型需要控制机器手臂连续按 4 个数字。

在 KITchen 任务中,模型需要连续操控四个家电。