
人类是擅于模仿的,我们和其他动物通过观察行为来模仿,理解它对环境状态的感知影响,并找出我们的身体可以采取什么行动来达到类似的结果。
对于机器人学习任务来说,模仿学习是一个强大的工具。但在这类环境感知任务中,使用强化学习来指定一个回报函数却是很困难的。
DeepMind最新论文主要探索了仅从第三人称视觉模仿操作轨迹的可能性,而不依赖action状态,团队的灵感来自于一个机器人机械手模仿视觉上演示的复杂的行为。
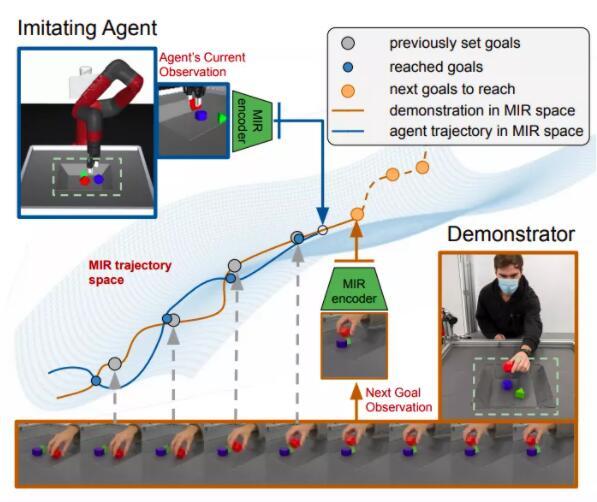
DeepMind提出的方法主要分为两个阶段:
1、提出一种操作器无关的表示(MIR, ManIPulation-Independent RepResentations),即不管是机械手、人手或是其他设备,保证这种表示都能够用于后续任务的学习
2、使用强化学习来学习action策略
与操作器无关的表示
领域适应性问题是机器人模拟现实中最关键的问题,即解决视觉仿真和现实之间的差别。
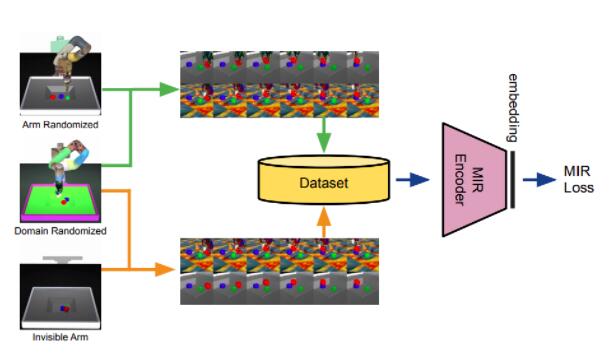
1、 随机使用各种类型操作器,各种仿真环境用来模拟现实世界
2、加入去除操作臂后的观察
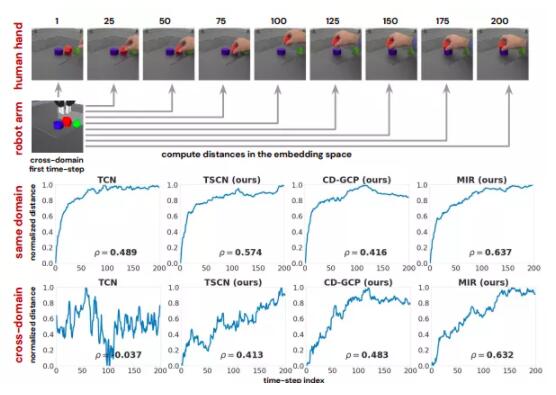
3、时序平滑对抗网络(TSCN, TeMpoRally-SMooth ContRastive NetwoRks),相比TCN来说,在softMax交叉熵目标函数中增加了一个分布系数p,使得学习过程更加平滑,尤其是在cRoSS-domain的情况。
使用强化学习
MIR表示空间的需求是actionable的,即可用于强化学习,表示为具体的action。
一个解决方案是使用goal-condITioned来训练策略,输入为当前状态o和目标状态g。这篇文章提出一种扩展方式,cRoSS-doMAIn goal-condITional policies,输入当前状态o和跨域的目标状态o””,最小化到达目标的行动次数。
数据和实验
研究小组在8个环境和场景(规范模拟、隐形手臂、随机手臂、随机域、Jaco Hand、真机器人、手杖和人手)上进行了实验,以评估通过未知机械手模拟无约束操作轨迹的性能。
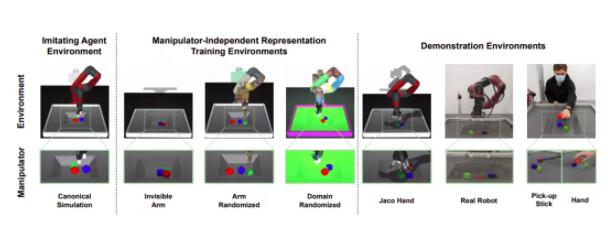
他们还用了一些基线方法,如朴素的goal condITioned plicies (GCP)和teMpoRal distance。
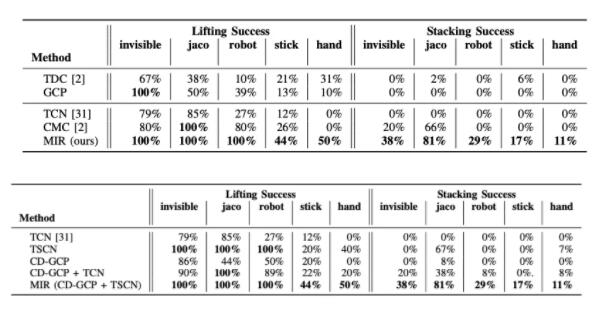
MIR 在所有测试领域都取得了最好的性能。它在叠加成功率方面的表现显著提高,并且以100% 的分数很好地模仿了模拟的 Jaco Hand 和 Invisible ARM。
这项研究论证了视觉模仿表征在视觉模仿中的重要性,并验证了操作无关表征在视觉模仿中的成功应用。
未来工厂中的机器人将拥有更强大的学习能力,并不局限于一种特定工具,一种特定任务。