
搞机器学习的人,很多都饱受数据管理的折磨。
要么是数据集老旧,需要手工修订标注。
要么是同一个数据集有很多被别人调整过的版本,无从下手。
或者,干脆没有合适数据集,需要自己建立。

国外,一位名叫SiMon LoUSky的程序员小哥终于不能忍了,开发出了一套用于机器学习的数据版本控制工具 (Data version ContRol,DVC)。
一键调用数据集、一键查看编辑历史&hellIP;&hellIP;最重要的是,在DVC工具背后,有一个GitHub一样的数据托管社区。
SiMon LoUSky在学生时代做项目时,就已经感受到了机器学习数据集管理不便的痛点。
当时,他的模型需要一个植物和花朵的数据进行训练,而开源数据集无论如何也得不到合理的结果。
于是他自己花了几个小时的时间,一一修正了数据集中大量过时、不合理的标注,之后训练结果让人十分满意。

除了这个项目,他之后又进行过很多数据集的修正、增补、创建工作,他把这些费时费力的工序称为“数据集的调试试错&Rdquo;,并且开始有意记录操作历史。
他逐渐发现,自己的项目中,数据管理总是一塌糊涂,而依靠GitHub托管的代码,却一直井井有条。
那为什么不做一个类似GitHub、专门服务数据管理的工具呢?
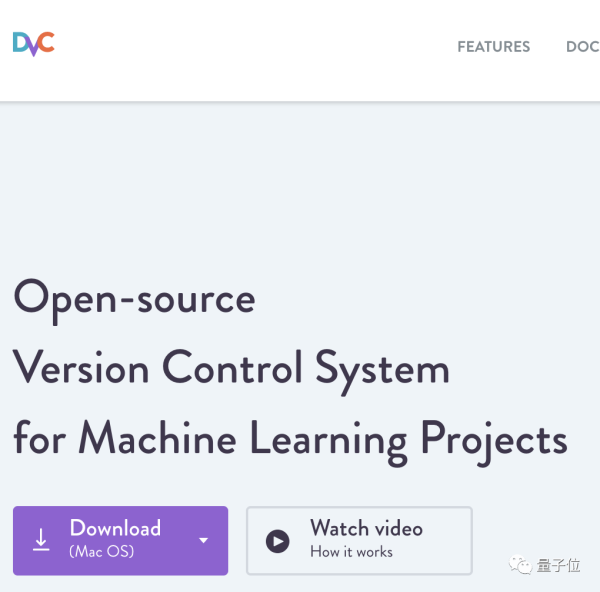
DVC就这样诞生了。
这是一个预装的工具库,实现功能包括对数据集的调用、历史操作信息的查看等等功能。
它的出现,意味着之前,研究人员在本地“死&Rdquo;的数据集上训练模型的方式彻底改变。
你可以将项目链接到在线托管的数据集(或任何文件),建立实时、准确的联系。数据集的任何更新变动,都能及时获知,方便项目的开展。
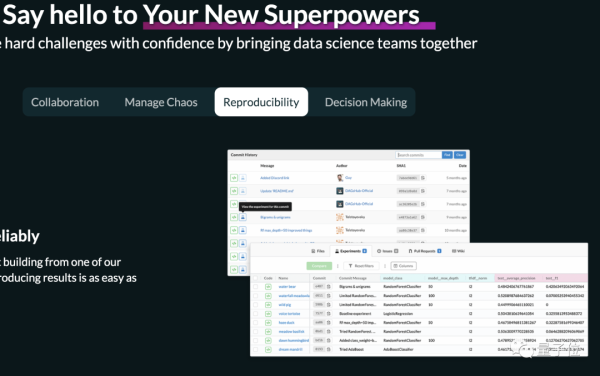
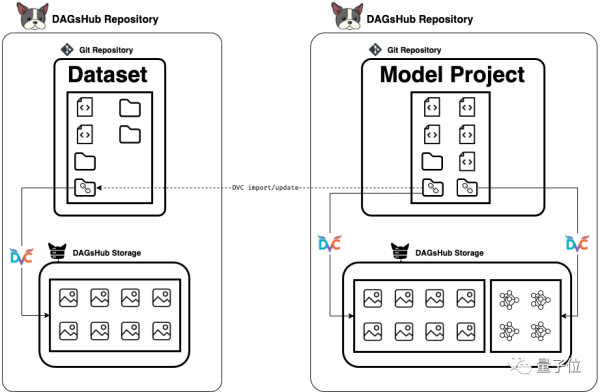
比如,现在有一个ReposiTory A,这是一个“活&Rdquo;数据集,其中元数据文件,指向存储在专用服务器的真实大文件。
用户可以将数据集文件组织到目录中,并添加带有utils函数的代码文件,以此来方便调用。
此外,还有一个ReposiTory B,这是对应机器学习项目,项目代码中,包含使用DVC导入数据集的指令。
只要创建一个数据注册表,就能建立A和B之间的联系:
MkdiR My-dataset &aMp;&aMp; cd My-dataset Git inIT dvc inIT
此时,数据集目录会是这样:
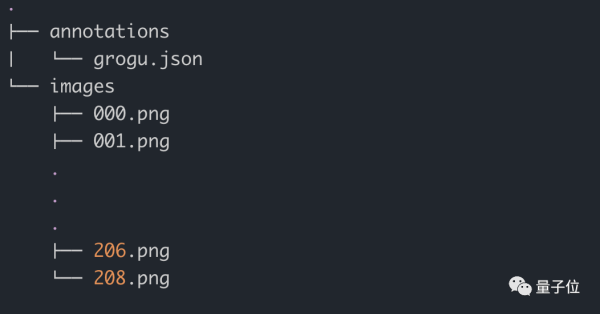
需要查看数据集相关信息时,输入指令:
dvc add annOTAtions dvc add images Git add . &aMp;&aMp; Git coMMIT -M “StaRting to Manage My dataset&Rdquo;
数据集的预览会保存到一个目录里,这个目录也会被DVC跟踪。
然后用户只需要把代码和数据推送到托管仓库,这样就随时随地访问它,并与其他人分享。
当然,DVC要发挥作用,自然少不了背后的DAGsHub。

DAGsHub就是一个GitHub的数据管理版本,由三部分组成,Git仓库、DVC、和机器学习流程平台Mlflow。
用户可以提交自己的项目,DAGsHub会自动扫描提交,并提取有用的信息,如实验参数,数据文件和模型的链接,并将它们结合到一个简单的界面。
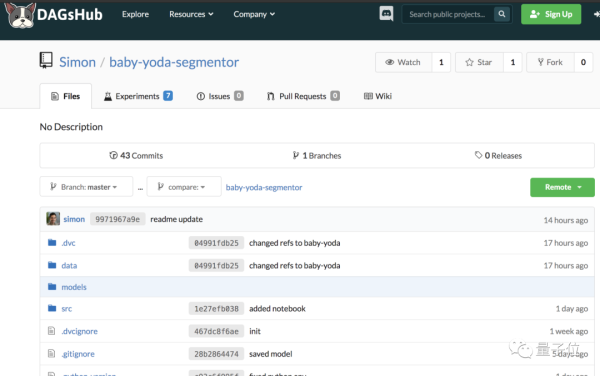
DAGsHub可以浏览和比较代码、数据、模型和实验,而且不需要下载任何东西。
此外,还能生成可视化数据管道、数据操作历史,并记录模型性能,自动且美观。
如何在机器学习项目中使用“活&Rdquo;数据集
要使用DAGsHub,只需要注册登录。
通过以下指令安装DVC:
pIP3 install dvc
在DAGsHub上找到一个数据集,如何在自己的模型中使用它呢?
首先,要从托管的数据集中导入一个目录,并把它当作原始文件:
MkdiR -p data/Raw dvc iMpoRt -o data/Raw/images https://dagshub.coM/SiMon/baby-yoda-segMentation-dataset data/images dvc iMpoRt -o data/Raw/annOTAtions https://dagshub.coM/SiMon/baby-yoda-segMentation-dataset data/annOTAtions
接着,图片和注释就会下载到你自己的项目中,并保留其中历史信息的信息。
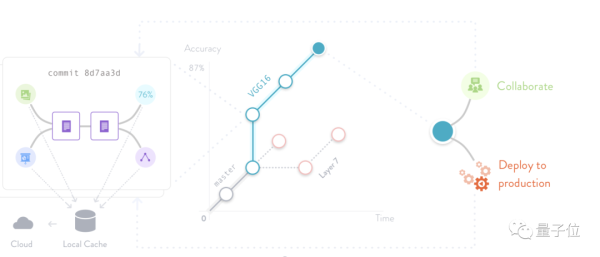
当你想要知道数据集的变更历史时,只需运行命令:
dvc update
就能将可视化结果返回默认目录保存:
是不是很方便?
对了,无论是DVC,还是DAGsHub,都是开源且免费的,赶快来试试吧