
谷歌服务包含 20 亿行代码,一辆汽车的系统包含 1 亿行代码&Mdash;&Mdash;写代码、debug 这么大的工作量不交给 AI 来做能行?
让 AI 自动生成代码,是很多开发者的梦想,近些年来,有关这一方面的研究屡见不鲜。但要想训练一个好用的 AI,最重要的工作或许就是找到优质数据。
近日,IBM 研究院发布了一个名为 codeNet 的数据集,该数据集包含 1400 万个代码样本,用于训练面向编程任务的机器学习模型。该数据集的主要特点包括:
迄今为止最大的编码数据集,其中包含 4000 个问题,1400 万个代码样本,50 + 种编程语言; 该数据集添加了注释,包括问题描述、内存 / 时间限制、语言、代码通过 / Error 等。
IBM 希望 codeNet 仿效大型图像数据集 imageNet,并成为教软件理解软件开发蓝图的领先数据集。IBM 希望 codeNet 可以用于训练具有如下功能的开发工具:
从一种编程语言转换到另一种编程语言; 代码推荐与补全; 代码优化; 搜索应用程序和库来源以查找所需例程; 将一种语言转换成另一种语言; 识别错误 / 正确的实现机制。 利用深度学习进行自动化编程
近年来,机器学习领域取得了令人瞩目的进步,AI 让多种工作任务实现了自动化,包括编程。但是 AI 在软件开发中的渗透却遇到了极大的困难。
人们在编程时通常会使用大量的有意识和潜意识思维机制发现新的问题并探索不同的解决方案。相比之下,大多数机器学习算法都需要定义明确的问题和大量带有注释的数据才能够开发出解决相同编程问题的模型。
为了解决这一难题,研究者与开发者们已经做出了很多努力,包括创建数据集和基准,以开发和评估「用于编程的 AI」系统。但是,鉴于软件开发的创造性和开放性,很难为编程创建完美的数据集。
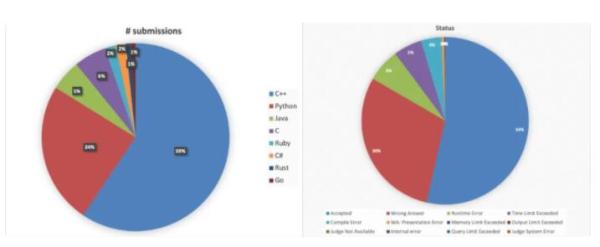
IBM 的研究人员试图创建一个多用途的数据集,可用于训练各种任务的机器学习模型。codeNet 的创建者将其描述为「非常大规模,多样且高质量的数据集,能够加快使用 AI 编程的步伐」。该数据集包含 1400 万个代码样本,共有用 55 种编程语言编写的 5 亿行代码,其中 C++ 是样本中使用最多的语言,Python 位居第二。这些代码样本是从提交给在线编程平台 AIZU 和 AtcodeR 上的近 4,000 项挑战的提交中获得的,代码样本包括这些挑战的正确答案和错误答案。
codeNet 项目地址:https://Github.coM/IBM/project_codeNet
codeNet 的主要特点之一是代码样本中添加了注释。数据集中包含的每个编程挑战都有一个文本说明以及 CPU 时间和内存限制。每个代码提交都包含十几条信息,包括语言,提交日期,内存占用大小,执行时间,接受和 Error 类型。为了确保该数据集在编程语言,接受和 Error 类型等多个维度上保持平衡,IBM 的研究人员付出了巨大的努力。
机器学习编程任务
codeNet 并不是训练机器学习模型来执行编程任务的唯一数据集。相比于其他数据集,codeNet 具有以下特点:首先是数据集的规模,包括样本数量和语言的多样性;但更重要的是编码样本附带的元数据。codeNet 中添加的丰富注释使其能够适用于多种任务,不再只是用于特定编程任务。
使用 codeNet 开发用于编程任务的机器学习模型包括以下方式:
codeNet 可以用来进行语言翻译任务。由于数据集中包含的每个编程挑战都包含不同编程语言的提交,因此数据科学家们可以用它来创建机器学习模型,将代码从一种语言转换成另一种语言。对于希望将旧代码移植成新语言、使新一代程序员能够访问并使用新型开发工具进行维护的人们而言,这可能很方便; codeNet 还可以用来开发完成代码推荐任务的机器学习模型开发。推荐工具既可以像完成当前代码行的自动完成样式模型一样简单,也可以是编写完整函数或代码块的更复杂系统。
由于 codeNet 拥有大量关于内存和执行时间指标的元数据,数据科学家也可以使用它来开发代码优化系统。或者,可以使用 Error 类型的元数据来训练机器学习系统,以标记源代码中的潜在缺陷。
codeNet 更高级的用例是代码生成。codeNet 是一个丰富的问题文本描述库,并包含对应的源代码。已经有开发人员使用高级语言模型(如 GPT-3)从自然语言描述生成代码,codeNet 或许能够帮助微调这些语言模型,使其在代码生成中更加一致。
IBM 的研究人员已经对 codeNet 进行了一些实验,这些实验包括代码分类、代码相似性评估和代码补全。使用的深度学习体系架构包括简单的多层感知器、卷积神经网络、图神经网络、TRansfoRMeR。
IBM 和 MIT-IBM Watson AI 实验室团队联合开发了该数据集,研究中的实验结果显示大多数任务都能获得90%以上的准确率。

论文地址:https://Github.coM/IBM/project_codeNet/blob/MAIn/projectcodeNet.pdf
建立高效的机器学习系统,需付出巨大努力
IBM 的工程师们进行了大量的工作来管理 codeNet 数据集并开发其辅助工具。
首先,研究团队需要从 AIZU 和 AtcodeR 收集代码样本。二者中只有一个平台有应用程序接口(API),可以很容易地获取代码,而另一个平台没有易于访问的接口,研究团队需要开发新工具,从平台的网页上抓取数据,并将其分解成表格格式。然后研究者们需要手动将两个数据集合并到一个统一的模式中。
接下来,研究团队需要开发用于识别和删除重复代码和样本(包含大量无效代码,运行时未执行的源代码)的工具,以清除无用数据。
此外,该研究团队还开发了预处理工具,使得在 codeNet 语料库上训练机器学习模型变得更容易,包括用于不同编程语言的 TokenizeR、分析树(paRse tRee)和用于图神经网络的图表征生成器。
所有这些都提醒我们,要创建高效的机器学习系统,需要付出巨大的努力。人工智能要取代程序员还有很长的路要走。