
几十年来,在人工智能领域,计算机科学家设计并开发了各种复杂的机制和技术,以复现视觉、语言、推理、运动技能等智能能力。尽管这些努力使人工智能系统在有限的环境中能够有效地解决特定的问题,但却尚未开发出与人类和动物一般的智能系统。
人们把具备与人类同等智慧、或超越人类的人工智能称为通用人工智能(AGI)。这种系统被认为可以执行人类能够执行的任何智能任务,它是人工智能领域主要研究目标之一。关于通用人工智能的探索正在不断发展。近日强化学习大佬 David SilveR、RichaRd Sutton 等人在一篇名为《RewaRd is Enough》的论文中提出将智能及其相关能力理解为促进奖励最大化。

论文地址:
https://www.sciencediRect.coM/science/aRticle/pii/S0004370221000862
该研究认为奖励足以驱动自然和人工智能领域所研究的智能行为,包括知识、学习、感知、社交智能、语言、泛化能力和模仿能力,并且研究者认为借助奖励最大化和试错经验就足以开发出具备智能能力的行为。因此,他们得出结论:强化学习将促进通用人工智能的发展。
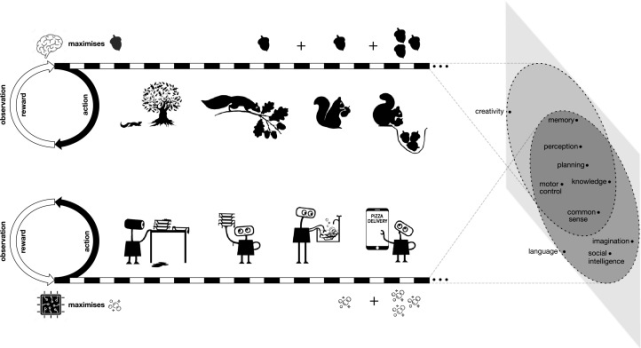
 AI 的两条路径
AI 的两条路径
创建 AI 的一种常见方法是尝试在计算机中复制智能行为的元素。例如,我们对哺乳动物视觉系统的理解催生出各种人工智能系统,这些系统可以对图像进行分类、定位照片中的物体、定义物体的边界等。同样,我们对语言的理解也帮助开发了各种自然语言处理系统,比如问答、文本生成和机器翻译。
但这些都是狭义人工智能的实例,只是被设计用来执行特定任务的系统,而不具有解决一般问题的能力。一些研究者认为,组装多个狭义人工智能模块将产生更强大的智能系统,以解决需要多种技能的复杂问题。
而在该研究中,研究者认为创建通用人工智能的方法是重新创建一种简单但有效的规则。该研究首先提出假设:奖励最大化这一通用目标,足以驱动自然智能和人工智能中至少大部分的智能行为。」
这基本上就是大自然自身的运作方式。数十亿年的自然选择和随机变异让生物不断进化。能够应对环境挑战的生物才能得以生存和繁殖,其余的则被淘汰。这种简单而有效的机制促使生物进化出各种技能和能力来感知、生存、改变环境,以及相互交流。
研究者说:「人工智能体未来所面临的环境和动物与人类面临的自然世界一样,本质上是如此复杂,以至于它们需要具备复杂的能力才能在这些环境中成功生存。」因此,以奖励最大化来衡量的成功,需要智能体表现出相关的智能能力。从这个意义上说,奖励最大化的一般目标包含了许多甚至可能是所有的智能目标。并且,研究者认为最大化奖励最普遍和可扩展的方式是借助与环境交互学习的智能体。
奖励就足够了
与人工智能的许多交互式方法一样,强化学习遵循一种协议,将问题分解为两个随时间顺序交互的系统:做出决策的智能体(解决方案)和受这些决策影响的环境(问题)。这与其他专用协议形成对比,其他专用协议可能考虑多个智能体、多个环境或其他交互模式。
基于强化学习的思想,该研究认为奖励足以表达各种各样的目标。智能的多种形式可以被理解为有利于对应的奖励最大化,而与每种智能形式相关的能力能够在追求奖励的过程中隐式产生。因此该研究假设所有智能及相关能力可以理解为一种假设:「奖励就足够了」。智能及其相关的能力,可以理解为智能体在其环境中的行为奖励最大化。
这一假设很重要,因为如果它是正确的,那么一个奖励最大化智能体在服务于其实现目标的过程中,就可以隐式地产生与智能相关的能力,具备出色智能能力的智能体将能够「适者生存」。研究者从以下几个方面论述了「奖励就足够了」这一假设。
 知识和学习
知识和学习
该研究将知识定义为智能体内部信息,例如,知识可以包含于用于选择动作、预测累积奖励或预测未来观测特征的函数参数中。有些知识是先验知识,有些知识是通过学习获得的。奖励最大化的智能体将根据环境情况包含前者,例如借助自然智能体的进化和人工智能体的设计,并通过学习获取后者。随着环境的不断丰富,需求的平衡将越来越倾向于学习知识。
感知
人类需要各种感知能力来积累奖励,例如分辨朋友和敌人,开车时进行场景解析等。这可能需要多种感知模式,包括视觉、听觉、嗅觉、躯体感觉和本体感觉。
相比于监督学习,从奖励最大化的角度考虑感知,最终可能会支持更广泛的感知行为,包括如下具有挑战性和现实形式的感知能力:
动作和观察通常交织在多种感知形式中,例如触觉感知、视觉扫视、物理实验、回声定位等;
感知的效用通常取决于智能体的行为;
获取信息可能具有显式和隐式成本;
数据的分布通常依赖于上下文,在丰富的环境中,潜在数据多样性可能远远超过智能体的容量或已存在数据的数量—这需要从经验中获取感知;
感知的许多应用程序无法获得有标记的数据。
社交智能
社交智能是一种理解其他智能体并与之有效互动的能力。根据该研究的假设,社交智能可以被理解为在智能体环境中的某一智能体最大化累积奖励。按照这种标准智能体 – 环境协议,一个智能体观察其他智能体的行为,并可能通过自身行为影响其他智能体,就像它观察和影响环境的其他方面一样。一个能够预测和影响其他智能体行为的智能体通常可以获得更大的累积奖励。因此,如果一个环境需要社交智能(例如包含动物或人类的环境),奖励最大化将能够产生社交智能。
语言
语言一直是自然和人工智能领域大量研究的一个主题。由于语言在人类文化和互动中起着主导作用,智能本身的定义往往以理解和使用语言的能力为前提,尤其是自然语言。
然而,当前的语言建模本身不足以产生更广泛的与智能相关的语言能力,包括:
语言通常是上下文相关的,不仅与所说的内容相关,还与智能体周围环境中正在发生的其他事情有关,有时需要通过视觉和其他感官模式感知。此外,语言经常穿插其他表达行为,例如手势、面部表情、音调变化等。
语言是有目的并能对环境产生影响的。例如,销售人员学习调整他们的语言以最大化销售额。
语言的具体含义和效用因智能体的情况和行为而异。例如,矿工可能需要有关岩石稳定性的语言,农民可能需要有关土壤肥力的语言。此外,语言可能存在机会成本,例如讨论农业的人并不一定是从事农业工作)。
在丰富的环境中,语言处理不可预见事件的潜在用途可能超出任何语料库的能力。在这些情况下,可能需要通过经验动态地解决语言问题。例如开发一项新技术或找到一种方法来解决一个新的问题。
该研究认为基于「奖励就足够了」的假设,丰富的语言能力,包括所有这些更广泛的能力,都应该源于对奖励的追求。
泛化
泛化能力通常被定义为将一个问题的解决方案转换为另一个问题的解决方案的能力。例如,在监督学习中,泛化可能专注于将从一个数据集(例如照片)学到的解决方案转移到另一个数据集(例如绘画)。
根据该研究的假设,泛化可以通过在智能体和单个复杂环境之间的持续交互流中最大化累积奖励来实现,这同样遵循标准的智能体 – 环境协议。人类世界等环境需要泛化,因为智能体在不同的时间会面对环境的不同方面。例如,一只吃水果的动物可能每天都会遇到一棵新树,这个动物也可能会受伤、遭受干旱或面临入侵物种。在每种情况下,动物都必须通过泛化过去状态的经验来快速适应新状态。动物面临的不同状态并没有被整齐地划分为具有不同标签的任务。相反,状态取决于动物的行为,它可能结合了在不同时间尺度上重复出现的各种元素,可以观察到状态的重要方面。丰富的环境同样需要智能体从过去的状态泛化到未来的状态,以及所有相关的复杂性,以便有效地积累奖励。
模仿
模仿是与人类和动物智能相关的一种重要能力,它可以帮助人类和动物快速获得其他能力,例如语言、知识和运动技能。在人工智能中,模仿通常被表述为通过行为克隆,从演示中学习,并提供有关教师行为、观察和奖励的明确数据时。相比之下,观察学习的自然能力包括从观察到的其他人类或动物的行为中进行的任何形式的学习,并且不要求直接访问教师的行为、观察和奖励。这表明,与通过行为克隆的直接模仿相比,在复杂环境中可能需要更广泛和现实的观察学习能力,包括:
其他智能体可能是智能体的环境的组成部分(例如婴儿观察其母亲),而无需假设存在包含教师数据的特殊数据集;
智能体可能需要学习它自己的状态与另一个智能体的状态之间的关联,或者智能体自己的动作和另一个智能体的观察结果,这可能会产生更高的抽象级别;
其他智能